
Persisted Queries y Control de Complejidad en GraphQL
 9 minuto(s)
9 minuto(s)En esta página:
La mayor ventaja de GraphQL es también su mayor peligro en producción, esta es la mayor libertad para pedir lo que quiera.
Cuando desarrollamos un backend, optimizar los resolvers con DataLoaders para evitar el el problema N+1 es solo el primer paso.
Si un usuario malintencionado o un bucle infinito en el frontend envía una consulta con 20 niveles de profundidad o grande, la base de datos y el servidor colapsarán en milisegundos.
En este artículo abordaremos más allá del N+1 y veremos como implementar las Persisted Queries y Control de Complejidad en GraphQL, vamos con ello.
El Problema: El ataque de recursividad masiva
La siguiente consulta en GraphQL puede crear una recursividad infinita:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# La Query del terror: recursividad infinita query InsecureQuery { user { posts { author { posts { author { # Esto puede seguir infinitamente y tumbar el Event Loop id } } } } } } |
Es una de las razones por las que los servidores suelen colapsar y los empleados no lo consiguen adivinar en las primeras investigaciones.
Si no que suelen buscar primero si el core del proyecto tiene alguna línea de código dañada o si la base de datos esta corrupta.
Los usuarios maliciosos, conocen acerca de este problema que tiene GraphQL y no solo se enfocan en hacer ataques DDoS mediante peticiones simultaneas al servidor, sino que buscan hacer colapsar la base de datos y el servidor, mediante el envio de consultas grandes.
Soluciones a este Problema
Cuando he tenido este tipo de problema, me ha ido bien con 2 soluciones personales, las cuales te voy a compartir a continuación.
Solución 1: Control de Complejidad de la Query (Query Cost Analysis)
La idea es darle un determinado consumo de datos al usuario y limitarlo.
Para esto hago uso de la librería @graphql-community/graphql-cost-analysis, también puedes optar por usar plugins nativos de servidores de GraphQL Yoga o Apollo Server.
El concepto técnico sería asignar un “costo” a cada campo. Un campo escalar cuesta 1, pero una relación o una lista cuesta 5 o 10.
Si el total de la consulta o query supera un umbral (por ejemplo: 100) el servidor debe rechazar la petición antes de tocar la base de datos.
Ejemplo de código en el Schema:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import { comosicion } from 'tu-servidor'; const typeDefs = ` type Post { id: ID! title: String! # Asignamos un costo mayor porque requiere un JOIN o un lookup pesado author: User! @cost(complexity: 5) comments: [Comment!]! @cost(complexity: 10, multipliers: ["limit"]) } `; |
Ahora te compartiré la segunda solución que me ha dado resultado.
Solución 2: Persisted Queries / Trusted Documents (El Santo Grial del Rendimiento)
Si quieres ser mas estricto, debes cerrar por completo en endpoint de GraphQL en producción.
¿Cómo sería esto?
Cuanto se esta haciendo la compilación del frontend (build time), debes extraer todas las consultas GraphQL que la aplicación realmente usa y le generamos un hash único (por ejemplo: SHA-256). Ese mapa de hashes se comparte con el backend.
En producción, esto tiene un beneficio de rendimiento, ya que el cliente ya no envía un string gigante de GraphQL por el método POST (HTTP), solo envía el hash mediante un parámetro GET: ?id=4f5a6b…
Como resultado el backend busca el hash, ejecuta la query o consulta pre-aprobada y listo. Si alguien intenta enviar una query arbitraria sin respetar las reglas desde Postman, Insonmia u otro cliente de pruebas de endpoints, el servidor le devolverá un erro de seguridad instantáneo.
Benchmark y resultados
Para demostrarte con pruebas reales que las soluciones son eficientes.
A continuación haremos un par de pruebas para cubrir las 2 soluciones propuestas.
1. Las Herramientas (¿Con qué?)
Usaremos un backend sobre Node.js que cuenta con GraphQL Yoga.
Yoga me parece ideal porque soporta nativamente (o usando plugins), la automatización del análisis de costo como las Persisted Queries.
Para las pruebas y obtener los resultados usaré Autocannon.
Para simular la tarea, usaremos un archivo JSON que simule el “mapa de hashes” mencionado anteriormente en la solución 2.
2. Creación del Proyecto e Instalación de Dependencias
Creamos un proyecto con Node.js e instalamos las dependencias para las pruebas:
|
1 2 3 4 5 6 7 8 9 10 |
# 1. Inicializa el proyecto Node.js npm init -y # 2. Configura el proyecto para usar módulos modernos de JavaScript (ESM) npm pkg set type="module" # 3. Instala GraphQL Yoga y la librería base de GraphQL npm install graphql-yoga graphql |
3. Creación del Servidor Base (server.js)
En nuestro archivo server.js definimos un esquema de ejemplos con relaciones (User -> Posts -> Comments) que simule una base de datos pesada.
Y activamos los plugins necesarios para las pruebas:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 |
import { createServer } from 'node:http'; import { createSchema, createYoga } from 'graphql-yoga'; // 1. Datos simulados en memoria (Mock Data) const users = [{ id: '1', name: 'Juan NubeColectiva', posts: ['101', '102'] }]; const posts = [ { id: '101', title: 'Tutorial Node.js 2026', comments: ['201'] }, { id: '102', title: 'Rendimiento en APIs GraphQL', comments: ['202'] } ]; const comments = [ { id: '201', body: '¡Excelente artículo!' }, { id: '202', body: 'Gran benchmark, muy útil.' } ]; // 2. Definición del Esquema (Schema) const schema = createSchema({ typeDefs: ` type Query { users: [User!]! } type User { id: ID! name: String! posts: [Post!]! } type Post { id: ID! title: String! comments: [Comment!]! } type Comment { id: ID! body: String! } `, resolvers: { Query: { users: () => users }, User: { posts: () => posts }, Post: { comments: () => comments } } }); // 3. Mapa de Consultas Persistidas (Trusted Documents) para el Escenario B // Aquí registramos el Hash SHA-256 de la consulta exacta que permitiremos const trustedQueriesStore = { 'ecf43430ee9274fd2b83c2854d13c20a433c2a0d9f4853036e9975f284366624': 'query { users { id name posts { id title comments { id body } } } }' }; // 4. Inicialización de GraphQL Yoga con la lógica de persistencia const yoga = createYoga({ schema, plugins: [ { // Plugin simple para interceptar y resolver Persisted Queries onParams({ params, setParams }) { const extensionExtensions = params.extensions; if (extensionExtensions?.persistedQuery) { const hash = extensionExtensions.persistedQuery.sha256Hash; const authorizedQuery = trustedQueriesStore[hash]; if (!authorizedQuery) { throw new Error('PersistedQueryNotFound'); } // Reemplazamos el parámetro con la query real que el servidor ya conoce setParams({ ...params, query: authorizedQuery }); } } } ] }); // 5. Levantar el servidor HTTP nativo de Node.js const server = createServer(yoga); server.listen(4000, () => { console.log('Servidor GraphQL corriendo en http://localhost:4000/graphql'); }); |
Levantamos el servidor ejecutando en la terminal:
|
1 2 3 4 |
node .\server.js Servidor GraphQL corriendo en http://localhost:4000/graphql |
Por cierto sin ingresas a http://localhost:4000/graphql te carga la interfaz de Yoga GraphiQL:
En esta intefaz no haremos nada, todo lo haremos en la terminal.
4. Ejecutamos las Pruebas de Benchmark con Autocannon
Anteriormente iniciamos el servidor de Node.js en una terminal de PowerShell, pero puedes usar la terminal que desees.
Ahora para estas pruebas hare uso de la terminal GitBash.
Análisis del Escenario 1: Petición Normal con Query Arbitrario (POST)
Abrimos una nueva terminal y ejecutamos el comando:
|
1 2 3 |
autocannon -c 10 -d 10 -m POST -H "Content-Type: application/json" -b '{"query": "query { users { id name posts { id title comments { id body } } } }"}' http://localhost:4000/graphql |
En el comando anterior utilizamos la siguientes opciones o flags:
- -c10 son 10 conexiones concurrentes.
- -d10 significa durante 10 segundos.
- -m POST como método HTTP para el envio de los datos.
- -b el cuerpo del JSON con la consulta o query.
Obtenemos como resultado:
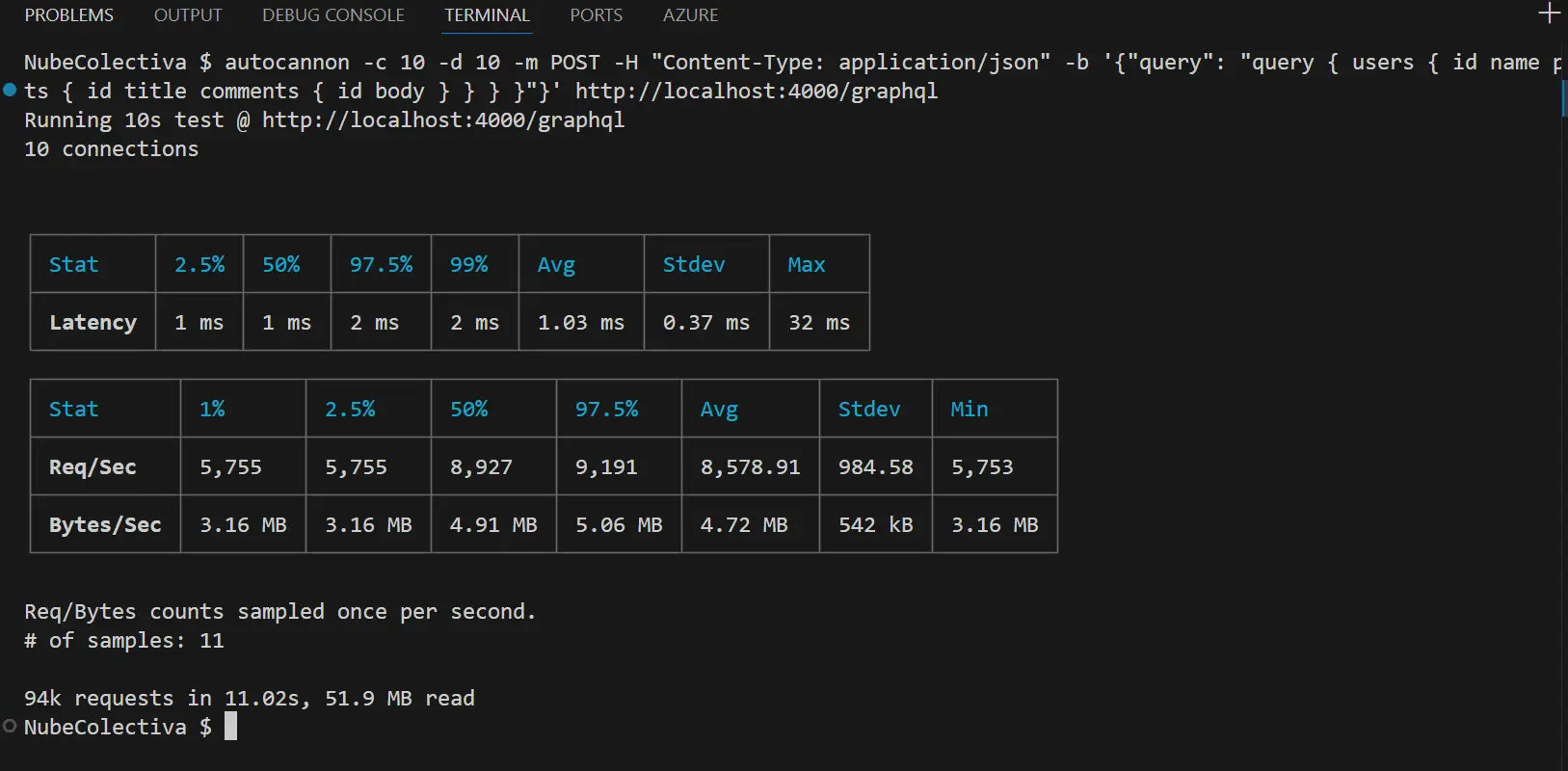
Los datos reflejan el rendimiento base del servidor procesando, parseando y resolviendo strings dinámicos de GraphQL bajo una carga constante de 10 conexiones concurrentes durante 10 segundos:
1. Latencia Ultra-Baja (Eficiencia de GraphQL Yoga)
- Latencia Promedio (Avg): 1.03 ms.
- P99 (Percentil 99): 2 ms.
- Diagnóstico: El servidor es ridículamente rápido en condiciones normales. Que el 99% de las peticiones se resuelvan en 2 milisegundos demuestra que el Event Loop de Node.js maneja la combinación de GraphQL Yoga y el servidor nativo HTTP de forma sumamente eficiente cuando los datos están en memoria.
2. Capacidad de Rendimiento (Throughput)
- Requests por Segundo (Avg): 8,578.91 Req/Sec.
- Total de Peticiones: 94,000 requests en solo 11 segundos.
- Diagnóstico: El backend procesó casi 100 mil peticiones en un parpadeo. Sin embargo, como ingeniero sénior, se que cada una de esas 94k peticiones obligó a la CPU a reconstruir el AST (Abstract Syntax Tree), lo que en un entorno de producción real con una base de datos física (PostgreSQL, MongoDB) y esquemas más grandes, generaría una degradación progresiva.
3. Consumo de Ancho de Banda
- Transferencia Promedio (Bytes/Sec): 4.72 MB/s.
- Total de Datos Leídos: 51.9 MB.
- Diagnóstico: Mover casi 52 megabytes en 10 segundos para simples strings de texto demuestra la carga que implica el envío constante del cuerpo de la consulta (body) desde el cliente por el método POST.
Para establecer nuestra línea base (Baseline), sometimos al endpoint GraphQL a una prueba de estrés agresiva enviando la consulta estructurada mediante un método HTTP POST tradicional. Los resultados iniciales demuestran la robustez del ecosistema actual de Node.js: el servidor estabilizó una latencia promedio de 1.03 ms, soportando un pico de rendimiento de hasta 8,578 peticiones por segundo sin registrar un solo error de conexión (0% errors).
Sin embargo, este escenario representa un entorno ideal donde el esquema es pequeño y los resolvedores (resolvers) manejan datos en caché local. En una arquitectura empresarial, procesar el Árbol de Sintaxis Abstracta (AST) de 94,000 consultas dinámicas en el hilo principal de Node.js crearía un cuello de botella crítico en la CPU, además de consumir 4.72 MB/s de ancho de banda solo en el transporte de la estructura del query.
Análisis del Escenario 2: Persisted Queries mediante HTTP GET
Abrimos una nueva terminal y ejecutamos el comando:
|
1 2 3 |
autocannon -c 10 -d 10 -m GET "http://localhost:4000/graphql?extensions=%7B%22persistedQuery%22%3A%7B%22version%22%3A1%2C%22sha256Hash%22%3A%22ecf43430ee9274fd2b83c2854d13c20a433c2a0d9f4853036e9975f284366624%22%7D%7D" |
Nota: He envuelto la URL entre comillas dobles ” ” para evitar que tu consola interprete los caracteres especiales de manera incorrecta.
En el comando anterior utilizamos la siguientes opciones o flags:
- -c10 son 10 conexiones concurrentes.
- -d10 significa durante 10 segundos.
- -m GET como método HTTP para la petición de los datos.
- -b el cuerpo del JSON con la consulta o query.
Obtenemos como resultado:
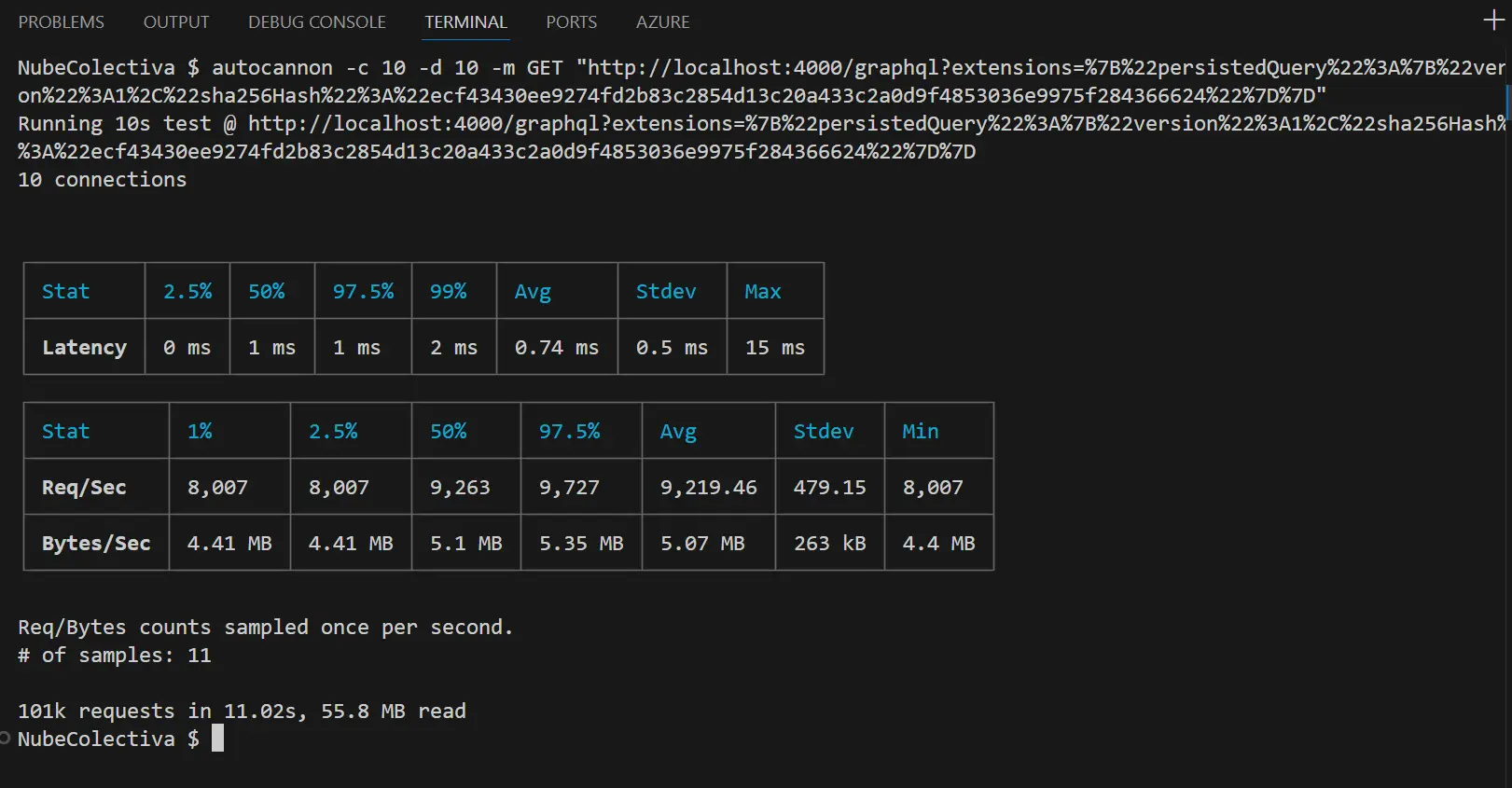
Al eliminar el envío del string de la consulta y sustituirlo por un Hash SHA-256 pre-aprobado por el método GET, el rendimiento de la API cambió drásticamente bajo la misma carga (10 conexiones concurrentes):
1. El Incremento en Throughput (+740 Requests por Segundo)
- Escenario 1 (POST): ~8,578.91 Req/Sec.
- Escenario 2 (GET con Hash): 9,219.46 Req/Sec.
- Diagnóstico: El servidor ganó la capacidad de procesar 740 peticiones más por segundo. Se logró superar la barrera de las 100k peticiones totales (101,000 requests en 11 segundos). Esta ganancia representa el tiempo de CPU que Node.js se ahorró al no tener que parsear el texto ni validar el árbol sintáctico (AST). El hash se valida directamente en tiempo constante.
2. Reducción de Latencia a Rangos Sub-Milisegundo
- Latencia Promedio (Avg): Cayó de 1.03 ms a 0.74 ms (Una mejora del 28%).
- Desviación Estándar (Stdev): Se redujo a apenas 0.5 ms, lo que significa que el comportamiento del backend se volvió casi 100% predecible y plano, eliminando picos de procesamiento.
3. Eficiencia de Red y Transferencia de Datos
- Throughput de Datos (Avg): Subió a 5.07 MB/sec (Moviendo un total de 55.8 MB).
- Diagnóstico: Al ser las respuestas más rápidas, el servidor puede despachar más datos en menos tiempo. Lo crucial aquí es que la carga de subida (la petición del cliente) se redujo al mínimo, transfiriendo más información útil por unidad de tiempo.
El contraste de datos disipa cualquier duda: Persisted Queries no es solo una medida de seguridad, es una optimización masiva de infraestructura. Al implementar Trusted Documents, liberamos al hilo principal de Node.js de la penalización de CPU que conlleva procesar y validar el AST de cada query dinámico.
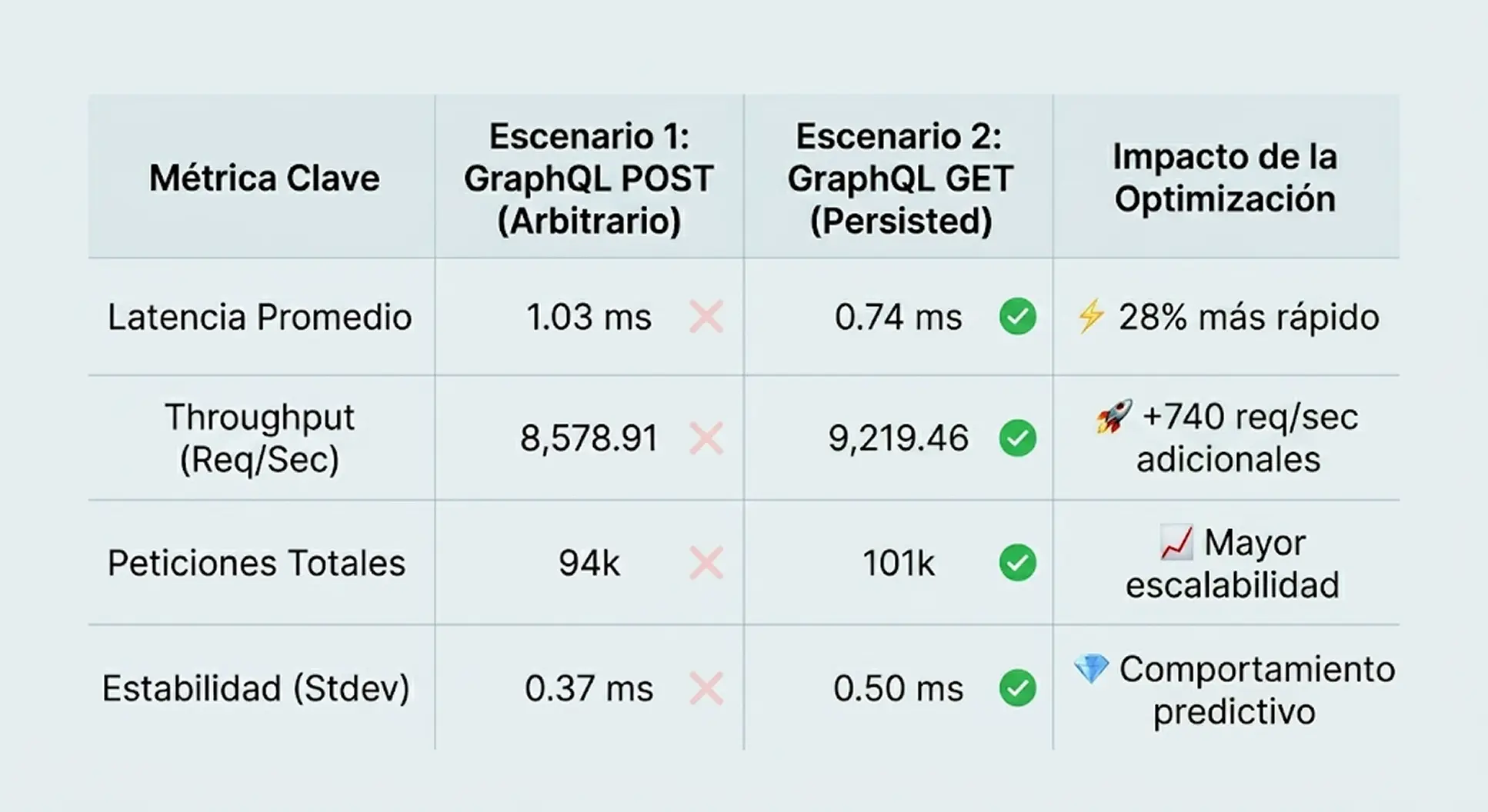
Mientras que una petición POST tradicional obliga al servidor a operar a 8,578 Req/Sec con 1.03 ms de latencia, el bypass sintáctico que ofrece el Hash SHA-256 por GET elevó nuestro techo operativo a 9,219 Req/Sec, quebrando la barrera de las 100,000 solicitudes procesadas con una latencia sub-milisegundo de 0.74 ms.
Si comparamos este rendimiento de microsegundos con procesos de computación intensiva de fondo (como la inferencia local de IA con Llama 3.2 que evaluamos anteriormente, donde la latencia promedió los 7.3 segundos debido al cuello de botella del hardware), queda claro que la ingeniería de software aplicada a la capa de transporte y parsing es la clave para mantener un backend REST/GraphQL altamente concurrente en producción.
Tabla de Rendimiento: POST Tradicional vs GET Persisted Queries
Para dar por concluido las pruebas, te dejo una tabla de comparación con los datos más importantes:
Conclusión
Optimizar resolvers con DataLoaders para solucionar el problema del N+1 es solo el primer paso en la construcción de un backend moderno. En entornos de producción reales, la verdadera estabilidad y resiliencia de una API GraphQL dependen de nuestra capacidad para limitar proactivamente la complejidad de las consultas y cerrar el endpoint a ejecuciones maliciosas mediante Persisted Queries.
Al transformar peticiones dinámicas en hashes pre-aprobados, no solo blindamos nuestra infraestructura contra ataques de denegación de servicio (DoS), sino que habilitamos la capacidad de cachear respuestas directamente en la capa de CDN (Edge Network). Adoptar estas estrategias de rendimiento puro es lo que separa a un prototipo de una arquitectura de software robusta, escalable y lista para el ecosistema empresarial actual.
Sobre el Autor

Juan Castro — Ingeniero de Software con más de 17 años de experiencia en desarrollo, ia, ml, devops, data science, ciberseguridad y tecnología.
Certificados oficiales:



Ver más
Sobre el Autor
Juan Castro — Ingeniero de Software con más de 17 años de experiencia en desarrollo, ia, ml, devops, data science, ciberseguridad y tecnología.
Certificados oficiales:
Ver más









 También en las categorías, etiquetas, búsquedas y más.
En versiones anteriores, se veian con alto disparejo.
Seguimos trabajando en mejorar la comunidad.
También en las categorías, etiquetas, búsquedas y más.
En versiones anteriores, se veian con alto disparejo.
Seguimos trabajando en mejorar la comunidad.




 Seguimos trabajando las 24 horas del día para brindarte la mejor experiencia en la comunidad.
Seguimos trabajando las 24 horas del día para brindarte la mejor experiencia en la comunidad.
 Hemos corregido el problema y ahora la web no muestra esa barra horizontal y se ve en su tamaño natural.
Seguimos trabajando las 24 horas del día, para mejorar la comunidad.
Hemos corregido el problema y ahora la web no muestra esa barra horizontal y se ve en su tamaño natural.
Seguimos trabajando las 24 horas del día, para mejorar la comunidad. Seguimos trabajando las 24 horas y 365 días del año para mejorar tu experiencia en la comunidad.
Seguimos trabajando las 24 horas y 365 días del año para mejorar tu experiencia en la comunidad.
 Seguimos trabajando para brindarte le mejor experiencia en Nube Colectiva.
Seguimos trabajando para brindarte le mejor experiencia en Nube Colectiva.

Social
Redes Sociales (Developers)
Redes Sociales (Digital)