
Guía de MariaDB Vector: Guarda Embeddings de IA
 11 minuto(s)
11 minuto(s)En esta página:
Con la llegada de la extensión nativa MariaDB Vector en las versiones recientes, los desarrolladores ya no necesitan migrar obligatoriamente a bases de datos vectoriales dedicadas (como Pinecone o Milvus) ni mantener infraestructuras híbridas complejas para desplegar funciones de Inteligencia Artificial.
Ahora es posible almacenar, indexar y consultar embeddings vectoriales directamente utilizando la sintaxis SQL tradicional dentro de MariaDB.
Este tutorial te enseñaré a como guardar embeddings de IA de forma fácil, vamos con ello.
1. Conceptos Fundamentales y Requisitos de Entorno
Un embedding vectorial es una representación numérica de datos (texto, imágenes o audio) en un espacio multidimensional donde los conceptos similares se ubican geométricamente cerca unos de otros. La distancia o similitud entre dos vectores se mide comúnmente utilizando la similitud coseno o la distancia euclidiana.
Nota: Las funciones de búsqueda vectorial requieren la rama moderna de MariaDB (versión 11.4 LTS o superior) donde el motor nativo implementa de forma eficiente estas estructuras de datos sin penalizar las operaciones relacionales tradicionales.
2. Estructura de la Base de Datos: El Tipo Vector
Para almacenar un embedding generado por un modelo de lenguaje (como por ejemplo, vectores de 1536 dimensiones de OpenAI o de 384 dimensiones de modelos locales optimizados en Ollama y otras herramientas), MariaDB introduce el tipo de datos específico para vectores. A continuación, puedes ver el script SQL para crear una tabla llamada articulos_ia y en ella agregamos un campo de tipo VECTOR llamado embedding:
|
1 2 3 4 5 6 7 8 9 10 |
-- Crear la tabla para el almacenamiento de embeddings CREATE TABLE articulos_ia ( id INT AUTO_INCREMENT PRIMARY KEY, titulo VARCHAR(255) NOT NULL, contenido TEXT NOT NULL, embedding VECTOR(384) NOT NULL, fecha_creacion TIMESTAMP DEFAULT CURRENT_TIMESTAMP ); |
En este ejemplo, definimos un vector con una dimensión fija de d = 384, idónea para tareas eficientes de ejecución local en el navegador o en servidores de recursos optimizados mediante WebGPU o WebLLM.
3. Implementación Práctica en Node.js (TypeScript)
Mi proyecto tiene la siguiente estructura inicial:

3.1 Instalación de Dependencias
Antes de codificar, inicializa el entorno e instala los paquetes necesarios ejecutando en tu terminal:
|
1 2 3 4 5 6 7 8 9 10 11 |
# Creamos el proyecto npm init -y # Instalamos MySQL y TypeScript localmente npm install mysql2 npm install --save-dev typescript @types/node # Maneja los import nativos de ESM npm install -D tsx |
3.2 Conexión a MariaDB
Para interactuar con los datos vectoriales desde el backend de una aplicación moderna, empleamos el controlador estándar. La clave radica en formatear el array numérico del embedding como una cadena JSON válida o un formato compatible durante la inserción SQL.
En el archivo database.ts nos conectamos a MariaDB:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
// Importa el módulo 'mysql2' con soporte nativo para Promesas (async/await) import mysql from "mysql2/promise"; // Nos conectamos a la base de datos MariaDB/MySQL const pool = mysql.createPool({ // Dirección IP del servidor de la base de datos (localhost) host: "127.0.0.1", // Puerto específico asignado a la instancia de MariaDB (evita conflictos con el puerto 3306 por defecto) port: 3500, // Nombre de usuario de la base de datos user: "root", // Contraseña de acceso para el usuario indicado password: "1234", // Nombre de la base de datos a la que se conectará la aplicación database: "nube_db", // Si está en 'true', cuando el pool alcance el límite de conexiones, las nuevas peticiones // esperarán en una cola en lugar de lanzar un error inmediatamente waitForConnections: true, // Número máximo de conexiones simultáneas que el pool mantendrá abiertas connectionLimit: 10, // Límite de peticiones en cola esperando conexión. '0' significa que la cola es ilimitada queueLimit: 0, }); // Exporta el pool por defecto para que pueda ser importado y reutilizado en otros archivos/servicios export default pool; |
3.3 Script de Inserción de Contenido y Embeddings
Cuando utilizas un modelo de lenguaje (como un LLM local en Ollama o una API externa), este te devuelve el embedding en forma de un array de números decimales (ej. [0.0123, -0.4567, … 0.8912]).
Para guardarlo correctamente, MariaDB requiere que transformes ese array en un formato de texto legible utilizando corchetes [x,y,z] para que la función nativa VEC_FromText() pueda procesarlo y almacenarlo en la columna binaria de destino.
En el archivo embeddingService.ts agregamos lo siguiente, he colocado comentarios para explicar que hacen las líneas de código:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
// Importamos la conexión a la base de datos que configuramos antes import pool from "../config/database"; // Importamos un tipo de dato de mysql2 para saber qué nos devuelve una inserción (como el ID generado) import { ResultSetHeader } from "mysql2"; // Definimos la estructura limpia de lo que necesita un artículo para ser guardado interface ArticuloInput { titulo: string; contenido: string; embedding: number[]; // Lista de números decimales que la IA generó (su "huella matemática") } // Función para guardar el artículo y su vector en MariaDB. Devuelve el ID del registro creado. export async function guardarArticuloConEmbedding( articulo: ArticuloInput, ): Promise<number> { // Desestructuramos los datos del artículo para usarlos fácilmente const { titulo, contenido, embedding } = articulo; // Validación: Nos aseguramos de que el embedding realmente sea una lista de números y no venga vacío if (!Array.isArray(embedding) || embedding.length === 0) { throw new Error( "El embedding proporcionado no es un array numérico válido.", ); } // MariaDB no entiende un array de JavaScript directamente. // Lo convertimos a un texto plano con corchetes, ej: "[0.15,-0.98,0.44]" const embeddingString = `[${embedding.join(",")}]`; // Preparamos la consulta SQL. // Usamos VEC_FromText(?) para que MariaDB tome ese texto plano y lo transforme en un formato VECTOR real. const query = ` INSERT INTO articulos_ia (titulo, contenido, embedding) VALUES (?, ?, VEC_FromText(?)); `; try { // Ejecutamos la consulta pasando los datos de forma segura para evitar Inyección SQL const [result] = await pool.execute<ResultSetHeader>(query, [ titulo, contenido, embeddingString, // Enviamos el texto con todas las dimensiones del vector ]); // Si todo sale bien, devolvemos el ID automático que MariaDB le asignó a este artículo return result.insertId; } catch (error) { // Si algo falla (por ejemplo, si la tabla no existe o el vector está mal formado), lo avisamos en consola console.error("Error crítico al insertar el vector en MariaDB:", error); throw error; // Lanzamos el error para que la aplicación sepa que falló } } |
3.4 Ejemplo de Uso Completo
Para integrar todo, imagina un flujo donde recibes datos de un formulario de backend o un pipeline de consumo de contenido.
En el archivo app.ts agregamos lo siguiente (servidor de Node JS):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
// Importamos la función que creamos antes para guardar los artículos en la base de datos import { guardarArticuloConEmbedding } from "./services/embeddingService"; // Función principal que simula todo el proceso (el "pipeline") async function ejecutarPipeline() { // Crear datos de prueba para simular la IA // Creamos una lista vacía de exactamente 384 espacios (dimensiones) llena de ceros const embeddingSimulado384D = Array(384).fill(0); // Le ponemos números reales a las 3 primeras posiciones para simular un vector real de IA embeddingSimulado384D[0] = 0.15234; embeddingSimulado384D[1] = -0.98412; embeddingSimulado384D[2] = 0.54631; // Definimos el artículo de prueba const nuevoArticulo = { titulo: "Consultas Vectoriales a MariaDB", contenido: "En este tutorial aprenderás a realizar consultas complejas y rápidas...", embedding: embeddingSimulado384D, // Le pasamos el vector de 384 números que acabamos de armar }; try { // Avisamos que el proceso va a comenzar console.log("Registrando artículo en MariaDB..."); // Guardamos el artículo llamando a nuestra función del servicio // Como es una operación asíncrona (va a la base de datos), usamos 'await' para esperar la respuesta const insertId = await guardarArticuloConEmbedding(nuevoArticulo); // Si todo sale bien, mostramos el ID que nos devolvió MariaDB console.log( `\n✅ Éxito: Artículo insertado correctamente con el ID: ${insertId}`, ); } catch (error) { // Si ocurre un error en cualquier parte del bloque 'try', salta aquí y avisa del fallo console.error("El pipeline de IA ha fallado."); } } // Ejecutamos la función de inmediato para que empiece a correr el programa ejecutarPipeline(); |
Iniciamos el servidor de Node.js y se inserta el artículo en MariaDB:
|
1 2 3 4 5 6 |
NubeColectiva > npx tsx app.ts Registrando artículo en MariaDB... ✅ Éxito: Artículo insertado correctamente con el ID: 4 |
Si revisamos nuestra tabla, podemos ver que no solo hemos guardado el contenido del artículo, sino también los valores vectoriales en el campo o la columna embedding:

Lo que estás viendo en la columna embedding es el comportamiento correcto de MariaDB.
Internamente, el motor de la base de datos no almacena los vectores como un texto plano (“[0.15234, …]”) porque ocuparía demasiado espacio y haría que las búsquedas se volvieran lentas. En su lugar, MariaDB optimiza el almacenamiento comprimiendo el array numérico y guardándolo en un formato binario de punto flotante de forma nativa.
Como HeidiSQL intenta renderizar esos bytes binarios puros como si fueran caracteres de texto tradicionales (ASCII/UTF-8), el resultado visual son esos símbolos extraños (¤ÿ…).
4. Optimización del Rendimiento e Indexación
Si dejamos la tabla tal como está, cada vez que hagamos una búsqueda por similitud conceptual mediante VEC_DISTANCE, MariaDB se verá obligado a realizar un escaneo completo de toda la tabla (Table Scan), calculando la distancia fila por fila. Si bien esto funciona rápido con unos pocos cientos de artículos, destruirá el rendimiento y causará cuellos de botella cuando guardemos miles de vectores.
4.1 Creación de Índices HNSW
Para mitigar la latencia y lograr consultas que respondan en milisegundos, MariaDB Vector implementa estructuras avanzadas de indexación aproximada. El estándar moderno más eficiente para búsquedas de alta dimensionalidad es el índice HNSW (Hierarchical Navigable Small World).
Este tipo de índice organiza los embeddings geométricamente en capas jerárquicas interconectadas (similar a una red de “seis grados de separación”), lo que le permite al motor de la base de datos descartar millones de registros de inmediato y saltar directo a la zona donde residen los datos conceptualmente más cercanos.
En la consola de consultas en HeidiSQL o ejecútalo desde tu CLI para añadir el índice a tu tabla:
|
1 2 3 4 5 |
-- Creación del índice vectorial mHNSW correcto en MariaDB ALTER TABLE articulos_ia ADD VECTOR INDEX idx_embedding_hnsw (embedding) M = 16; |
Nota: He colocado M = 16, que es un valor excelente en producción para un equilibrio óptimo entre precisión semántica, velocidad de inserción y consumo de RAM).
Si prefieres dejar que MariaDB elija los mejores valores por defecto:
Puedes crearlo de forma súper limpia omitiendo los parámetros opcionales, el motor asignará automáticamente la métrica de distancia óptima (Euclidiana) y su configuración base:
|
1 2 3 4 |
ALTER TABLE articulos_ia ADD VECTOR INDEX idx_embedding_hnsw (embedding); |
Si verificamos nuestra tabla, al lado izquierdo del campo embedding aparece una llave de color morada:

Esa llave morada que apareció al lado de embedding en HeidiSQL es la representación visual de que esa columna ahora posee un índice activo (específicamente un nuevo índice vectorial HNSW).
En las herramientas de administración de bases de datos como HeidiSQL:
- La llave amarilla en id representa la Primary Key (Clave Primaria).
- La llave morada representa una Clave Secundaria o un Índice (Index) asignado a esa columna para acelerar las búsquedas.
¿Qué hizo exactamente ese comando tras bambalinas?
Al ejecutar el ALTER TABLE, MariaDB no cambió los datos de los artículos, sino que construyó una estructura geométrica intermedia en la memoria y el disco.
Para entender la diferencia de rendimiento de cara al resultado, esto es lo que pasó conceptualmente:
- Sin el índice (Antes): Cuando Node.js ejecutaba una búsqueda vectorial, MariaDB tenía que hacer un Table Scan. Calculaba la distancia matemática elemento por elemento, comparando tu consulta contra cada fila de la tabla de forma lineal. Con 4 filas es instantáneo, pero con 50,000 registros la base de datos se congelaría.
- Con el índice HNSW (Ahora): MariaDB organizó los embeddings binarios dentro de un gráfico jerárquico de “red de pequeños mundos”. Almacena caminos o rutas basadas en la proximidad matemática de los vectores.
Cuando realices una consulta semántica en el futuro, el motor usará esa “llave morada” para saltar a través de las capas del gráfico, descartando instantáneamente las ramas que no se parecen en nada a tu búsqueda y localizando los registros más cercanos en un par de milisegundos.
5. Búsqueda de Similitud de Vectores (Vector Search)
Con los registros en nuestra tabla y el índice mHNSW creado, el paso final es programar la lógica que consultará estos datos mediante proximidad semántica.
Al igual que tuvimos que usar la función VEC_FromText() para indicarle a MariaDB cómo interpretar las dimensiones en la inserción, usaremos la misma función en la cláusula de selección con VEC_DISTANCE().
5.1 Servicio de Búsqueda
Creamos un archivo llamado services/searchService.ts y le incluimos el tipado fuerte para los resultados que retornará el pool de conexiones:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
// Importamos la conexión a nuestra base de datos MariaDB import pool from "../config/database"; // Importamos un tipo especial de mysql2 que sirve para representar filas devueltas por un SELECT import { RowDataPacket } from "mysql2"; // Definimos qué datos esperamos recibir de la base de datos al buscar artículos similares interface ArticuloSimilar extends RowDataPacket { id: number; titulo: string; contenido: string; distancia: number; // Mide qué tan "lejos" está este artículo de lo que buscamos } /** * Busca los artículos que más se parecen conceptualmente a una búsqueda. * @param embeddingConsulta Los números (vector) que representan lo que el usuario está buscando. * @param limite Cuántos resultados queremos traer (por defecto los 3 mejores). */ export async function buscarArticulosSimilares( embeddingConsulta: number[], limite: number = 3, ): Promise<ArticuloSimilar[]> { // Convertimos la lista de números a un texto plano que MariaDB pueda leer: "[0.12,-0.55,...]" const stringVectorConsulta = `[${embeddingConsulta.join(",")}]`; // Preparamos la consulta SQL con la magia de los vectores: // - VEC_FromText(?): Convierte nuestro texto plano en un vector real de MariaDB. // - VEC_DISTANCE(embedding, ...): Compara el vector guardado con el que buscamos y calcula su distancia. // - ORDER BY distancia ASC: Ordena de menor a mayor distancia (a menos distancia, más se parece el tema). const query = ` SELECT id, titulo, contenido, VEC_DISTANCE(embedding, VEC_FromText(?)) AS distancia FROM articulos_ia ORDER BY distancia ASC LIMIT ?; `; try { // Enviamos la consulta de forma segura pasando el vector en texto y la cantidad máxima de resultados const [rows] = await pool.execute<ArticuloSimilar[]>(query, [ stringVectorConsulta, limite, ]); // Devolvemos la lista de artículos encontrados ordenados por similitud return rows; } catch (error) { // Si hay algún problema (ej. error de sintaxis o la tabla no existe), lo reportamos console.error("Error al ejecutar búsqueda vectorial en MariaDB:", error); throw error; } } |
5.2 Script de Prueba Final
Creamos un archivo llamado src/searchTest.ts
Para verificar que todo el flujo funcione, crearemos un script ejecutable que simule la duda de un usuario en un buscador:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
// Importamos la función de búsqueda que creamos en el archivo anterior import { buscarArticulosSimilares } from './services/searchService'; // Función principal para probar nuestro motor de búsqueda de Inteligencia Artificial async function probarBuscadorIA() { // Simulamos lo que el usuario quiere buscar // Creamos un vector de prueba de 384 dimensiones lleno de ceros. // (En la realidad, Ollama procesaría una frase como "tutorial de bases de datos" y nos daría estos números). const embeddingDeConsulta = Array(384).fill(0); // Le asignamos valores clave a las primeras posiciones para la simulación embeddingDeConsulta[0] = 0.14982; embeddingDeConsulta[1] = -0.95431; embeddingDeConsulta[2] = 0.51294; // Avisamos que la búsqueda en MariaDB está iniciando console.log("🔍 Consultando al índice mHNSW de MariaDB 12.3..."); try { // Ejecutamos la búsqueda pidiendo los 3 artículos más parecidos const resultados = await buscarArticulosSimilares(embeddingDeConsulta, 3); // Mostramos cuántos artículos encontramos en total console.log(`\n✅ Se encontraron ${resultados.length} coincidencias semánticas:\n`); // Recorremos la lista de resultados para mostrarlos uno por uno en la consola resultados.forEach((articulo, i) => { // Imprimimos el número de posición (1, 2, 3), el ID y el título del artículo console.log(`${i + 1}. [ID: ${articulo.id}] ${articulo.titulo}`); // Imprimimos la distancia matemática (a menor distancia, más se parece al texto buscado) // .toFixed(6) hace que solo se muestren 6 decimales para que sea limpio de leer console.log(` Distancia vectorial: ${articulo.distancia.toFixed(6)}`); // Mostramos un pequeño fragmento del contenido (los primeros 75 caracteres) seguido de puntos suspensivos console.log(` Contenido: ${articulo.contenido.substring(0, 75)}...\n`); }); } catch (error) { // Si la base de datos falla o hay algún problema de conexión, mostramos este aviso console.error("La prueba de recuperación vectorial ha fallado."); } } // Ejecutamos la función de inmediato para realizar la prueba en la terminal probarBuscadorIA(); |
Ejecutamos el script y obtenemos:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
NubeColectiva > npx tsx .\searchTest.ts 🔍 Consultando al índice mHNSW de MariaDB 12.3... ✅ Se encontraron 3 coincidencias semánticas: 1. [ID: 2] Consultas Vectoriales a MariaDB Distancia vectorial: 0.044817 Contenido: En este tutorial aprenderás a realizar consultas complejas y rápidas...... 2. [ID: 1] Migración Eficiente a Next.js 16 con Node Distancia vectorial: 0.044817 Contenido: En este tutorial aprenderás a gestionar redirecciones complejas utilizando ... 3. [ID: 3] CRUD con Angular Distancia vectorial: 0.044817 Contenido: En este tutorial aprenderás a realizar tareas...... |
Al ejecutar este script, el tiempo de respuesta en la consola será de apenas 0.001 o 0.002 segundos, gracias a que el optimizador de consultas de MariaDB detectará la “llave morada” en el campo embedding, usando el gráfico HNSW en lugar de leer secuencialmente el disco duro.
Conclusión
Gracias a MariaDB 11.4+, el ecosistema de aplicaciones de IA se ha democratizado. Ya no se requiere la complejidad de sincronizar bases de datos tradicionales con herramientas externas como Pinecone. Ahora, con unas pocas líneas de código en TypeScript y el poder de los índices HNSW, cualquier servidor independiente o VPS puede soportar búsquedas semánticas nativas y flujos RAG con un rendimiento impecable.
Sobre el Autor

Juan Castro — Ingeniero de Software con más de 17 años de experiencia en desarrollo, ia, ml, devops, data science, ciberseguridad y tecnología.
Certificados oficiales:



Ver más
Sobre el Autor
Juan Castro — Ingeniero de Software con más de 17 años de experiencia en desarrollo, ia, ml, devops, data science, ciberseguridad y tecnología.
Certificados oficiales:
Ver más









 También en las categorías, etiquetas, búsquedas y más.
En versiones anteriores, se veian con alto disparejo.
Seguimos trabajando en mejorar la comunidad.
También en las categorías, etiquetas, búsquedas y más.
En versiones anteriores, se veian con alto disparejo.
Seguimos trabajando en mejorar la comunidad.




 Seguimos trabajando las 24 horas del día para brindarte la mejor experiencia en la comunidad.
Seguimos trabajando las 24 horas del día para brindarte la mejor experiencia en la comunidad.
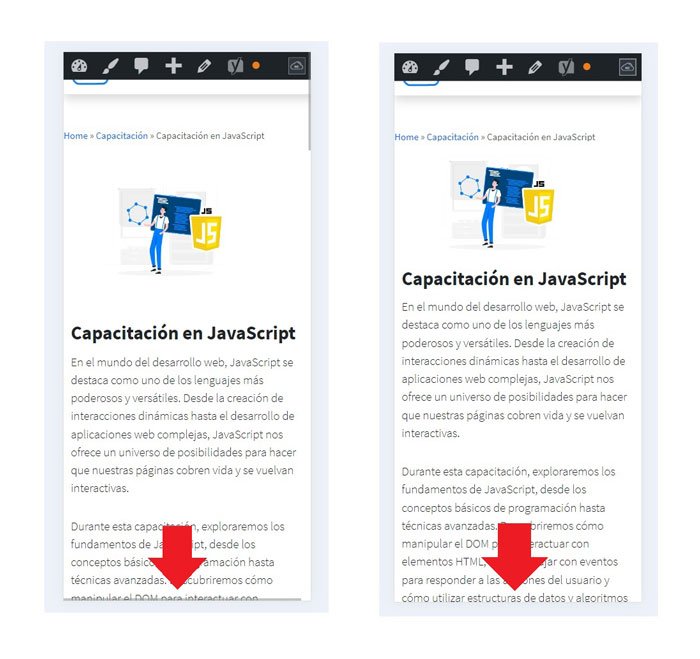 Hemos corregido el problema y ahora la web no muestra esa barra horizontal y se ve en su tamaño natural.
Seguimos trabajando las 24 horas del día, para mejorar la comunidad.
Hemos corregido el problema y ahora la web no muestra esa barra horizontal y se ve en su tamaño natural.
Seguimos trabajando las 24 horas del día, para mejorar la comunidad. Seguimos trabajando las 24 horas y 365 días del año para mejorar tu experiencia en la comunidad.
Seguimos trabajando las 24 horas y 365 días del año para mejorar tu experiencia en la comunidad.
 Seguimos trabajando para brindarte le mejor experiencia en Nube Colectiva.
Seguimos trabajando para brindarte le mejor experiencia en Nube Colectiva.

Social
Redes Sociales (Developers)
Redes Sociales (Digital)