
Cómo Usar PostgreSQL como Base de Datos Vectorial (IA)
 13 minuto(s)
13 minuto(s)En esta página:
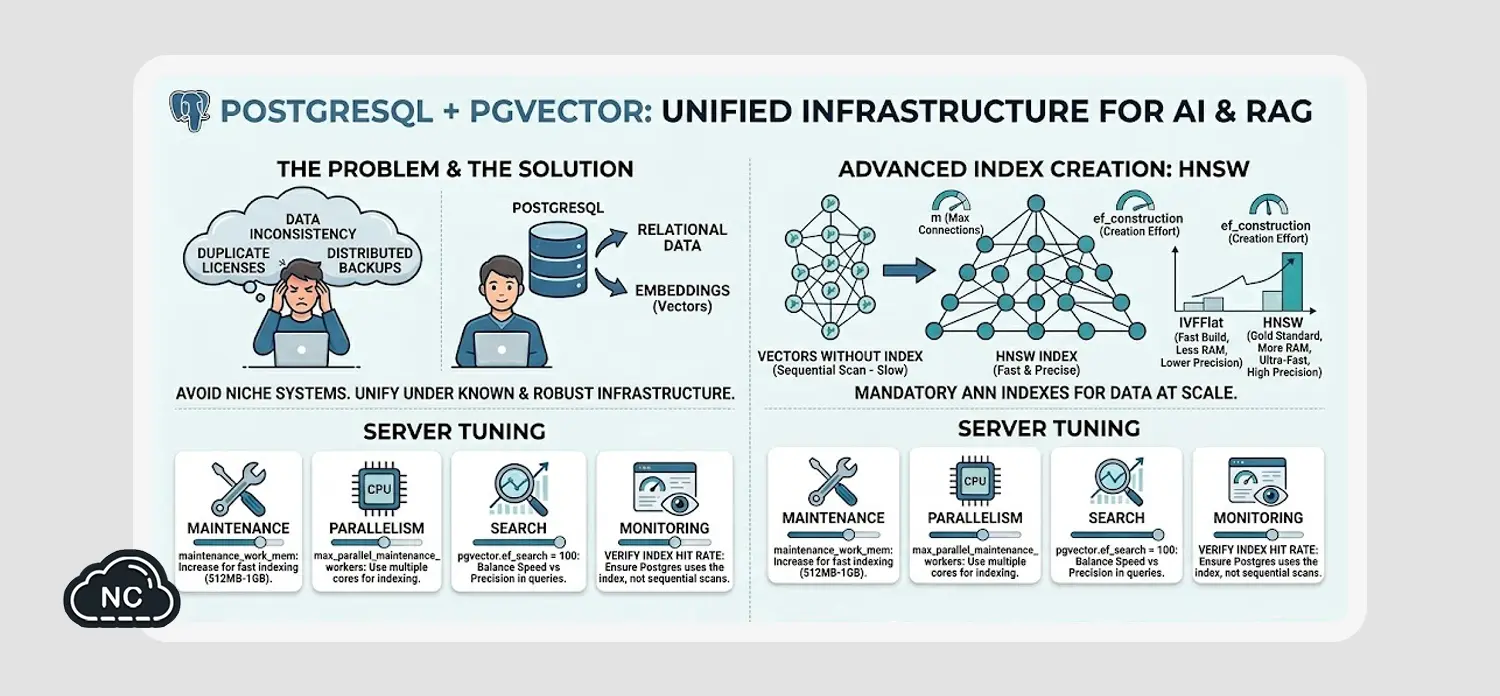
Con la explosión de los Modelos de Lenguaje (LLMs) y los sistemas RAG (Retrieval-Augmented Generation), almacenar embeddings se volvió una necesidad crítica.
Aunque el mercado se llenó de bases de datos vectoriales nativas y dedicadas, la realidad de la ingeniería de producción es otra: mantener la consistencia de los datos, gestionar copias de seguridad distribuidas y pagar licencias duplicadas es un dolor de cabeza.
La base de datos PostgreSQL, gracias a la madurez de su extensión pgvector, nos permite unificar el mundo relacional y el vectorial bajo una misma infraestructura robusta y conocida.
1. Introducción y Conceptos importantes
Antes de ir a la parte técnica, es importante conocer ciertos puntos:
¿Qué pasa bajo el capó de un Vector en Postgres?
Un embedding no es más que una representación matemática de un texto, imagen o audio en forma de una lista ordenada de números de punto flotante (un array). La dimensión de este vector depende exclusivamente del modelo de Inteligencia Artificial que utilices. Por ejemplo, si usas un modelo local ligero como all-MiniLM-L6-v2 para priorizar la privacidad, trabajarás con 384 dimensiones. Si optas por modelos comerciales en la nube, la cifra ascenderá a 1536 dimensiones.
Para habilitar el soporte nativo de estos elementos en tu base de datos, solo necesitas ejecutar el siguiente bloque SQL para inicializar la extensión y definir tu primera tabla optimizada:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-- Habilitar la extensión de vectores en tu base de datos CREATE EXTENSION IF NOT EXISTS vector; -- Crear una tabla estructurada para almacenar embeddings de IA CREATE TABLE articulos_ia ( id SERIAL PRIMARY KEY, titulo TEXT NOT NULL, contenido TEXT NOT NULL, embedding vector(384) -- Ajusta las dimensiones según tu modelo local o en la nube ); |
Búsquedas Secuenciales vs Búsquedas Indexadas
El verdadero problema cuando llevas una aplicación con IA a producción es la escala de datos. Si ejecutas una búsqueda semántica utilizando operadores de distancia tradicionales de pgvector (como <=> para la distancia del coseno), PostgreSQL realizará por defecto un Sequential Scan.
|
1 2 3 4 5 6 7 |
-- Query de búsqueda semántica (Peligroso sin índices en tablas grandes) SELECT id, titulo, contenido, (embedding <=> '[0.012, -0.023, ..., 0.145]') AS distancia FROM articulos_ia ORDER BY distancia ASC LIMIT 5; |
Cuando tu tabla posee unos pocos miles de filas, este cálculo matemático en tiempo real tarda microsegundos. Sin embargo, si almacenas millones de fragmentos de texto, la CPU se verá obligada a calcular la distancia geométrica fila por fila en cada petición, destruyendo por completo los tiempos de respuesta de tu API backend.
Infraestructura unificada para IA y RAG
Si tu aplicación necesita guardar datos comunes (usuarios, configuraciones, textos) y, además, los vectores de tu IA, PostgreSQL es la opción más robusta y confiable porque no necesitas mantener dos bases de datos separadas. Te permite hacer consultas complejas combinando datos relacionales y vectores en una sola línea de SQL (un JOIN de toda la vida).
 |
 |
Solo valdría la pena mirar opciones como Chroma o Qdrant si estás haciendo un proyecto donde únicamente vas a buscar vectores y no te importa la estructura relacional, o Redis si la velocidad de respuesta en memoria es tu prioridad absoluta.
La Solución Avanzada: Índices HNSW vs IVFFlat
Para evitar el colapso del servidor, es obligatorio implementar índices de búsqueda aproximada de vecinos más cercanos (ANN). En pgvector, se puede manejar dos estrategias principales con ventajas muy claras según tu infraestructura:
- IVFFlat (Inverted File Flat): Funciona dividiendo el espacio de tus vectores en listas o clústeres. Su principal beneficio es que se construye de manera muy rápida y consume una cantidad mínima de memoria RAM. Su desventaja es que, si nuevos vectores se agrupan demasiado cerca en producción, puedes llegar a perder precisión en los resultados semánticos.
- HNSW (Hierarchical Navigable Small World): Es el estándar de oro actual en la ingeniería de datos. Construye un grafo multicapa donde cada vector se conecta con sus vecinos más cercanos. Aunque requiere una mayor cantidad de memoria RAM y el tiempo inicial de creación del índice es más elevado, ofrece una velocidad de consulta increíblemente rápida y una precisión semántica implacable bajo alta concurrencia.
Para optimizar un entorno de producción exigente, la implementación recomendada de un índice HNSW ajustando los hiperparámetros críticos (m para las conexiones máximas por nodo y ef_construction para el esfuerzo de exploración del grafo) se realiza de la siguiente manera:
|
1 2 3 4 5 6 |
-- Creación de un índice HNSW optimizado para alta precisión CREATE INDEX ON articulos_ia USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64); |
Configuración y Tuning del Servidor
La construcción de grafos vectoriales es una tarea que consume recursos intensivos a nivel de hardware. Si dejas la configuración por defecto de PostgreSQL, el comando de indexación fallará o tardará horas. Modifica los siguientes parámetros directamente en tu archivo postgresql.conf para acelerar los despliegues:
- maintenance_work_mem: Eleva temporalmente este valor (por ejemplo, a 512MB o 1GB). La creación de grafos HNSW se realiza enteramente en la memoria RAM asignada a tareas de mantenimiento; si el espacio es insuficiente, Postgres paginará en disco, ralentizando el proceso.
- max_parallel_maintenance_workers: pgvector tiene la capacidad nativa de compilar índices utilizando múltiples núcleos en paralelo. Asigna 2 o 4 núcleos dedicados a este proceso según la capacidad de tu droplet o servidor cloud para reducir el tiempo de indexación a unos pocos minutos.
pgvector, el parámetro ef_search controla el balance exacto entre velocidad y precisión en el momento de realizar una consulta. Por defecto, su valor viene configurado en 40. Si notas que tu sistema RAG está devolviendo respuestas imprecisas o contextos erróneos bajo estrés, ejecuta el comando SET pgvector.ef_search = 100; justo antes de lanzar tu consulta. Esto incrementará el rango de exploración dentro del grafo, elevando notablemente la calidad del contexto inyectado al LLM con un impacto prácticamente imperceptible en la latencia general de tu API.¿Cómo saber si tu índice está funcionando?
Una trampa común en la que caen muchos desarrolladores es crear el índice HNSW y asumir que todo está solucionado. En producción, necesitas medir el Index Hit Rate (la tasa de éxito del índice). Si realizas búsquedas semánticas y PostgreSQL sigue recurriendo a lecturas secuenciales en disco, tu optimización no está sirviendo de nada.
Puedes verificar el estado real de tus índices vectoriales ejecutando la siguiente consulta de diagnóstico:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT schemaname, relname AS tabla, indexrelname AS indice, idx_scan AS busquedas_indexadas, idx_tup_read AS tuplas_leidas FROM pg_stat_user_indexes WHERE indexrelname LIKE '%hnsw%' OR indexrelname LIKE '%ivfflat%'; |
Si el valor de busquedas_indexadas se mantiene en cero después de lanzar tus pruebas de estrés, significa que el planificador de consultas de PostgreSQL decidió que es más “barato” hacer un escaneo secuencial. Esto ocurre habitualmente por dos razones: la tabla contiene muy pocos datos para justificar el uso del grafo, o el parámetro work_mem del servidor es tan bajo que el índice no cabe en la memoria de trabajo durante la ejecución del query.
2. Cómo Usar PostgreSQL como Base de Datos Vectorial (IA)
Estoy usando PostgreSQL 17.10 en Windows 11 via Docker Desktop.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# Crear y levantar el contenedor de PostgreSQL Nube Colectiva > docker run --name pg-server -e POSTGRES_PASSWORD=tu_contraseña_segura -p 5432:5432 -v pgdata:/var/lib/postgresql/data -d postgres:17 # Verificar que ya está funcionando Nube Colectiva >docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES b481230636c3 postgres:17 "docker-entrypoint.s…" 13 hours ago Up 3 minutes 0.0.0.0:5432->5432/tcp, [::]:5432->5432/tcp pg-server # Ver la versión de PostgreSQL Nube Colectiva > docker exec -it pg-server postgres --version postgres (PostgreSQL) 17.10 (Debian 17.10-1.pgdg13+1) |
Tu puedes usar PostgreSQL de la manera que mejor te paresca.
Paso 1: Instalar pgvector
Ejecuta los siguientes comandos en tu PowerShell de Windows (uno por uno). Esto entrará al contenedor como superusuario (root) e instalará el paquete oficial de pgvector para PostgreSQL 17:
|
1 2 3 4 |
docker exec -it --user root pg-server apt-get update docker exec -it --user root pg-server apt-get install -y postgresql-17-pgvector |
Paso 2: Entrar a Postgres y crear la tabla
Una vez que termine de instalarse pgvector, necesitamos una tabla para guardar nuestros datos vectoriales.
Ingresa a tu consola de Postgres:
|
1 2 3 |
docker exec -it pg-server psql -U postgres |
Ejecuta los comandos:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-- 1. Habilitar la extensión de pgvector CREATE EXTENSION IF NOT EXISTS vector; -- 2. Crear la tabla para Nomic de 768 dimensiones CREATE TABLE articles_ia ( id SERIAL PRIMARY KEY, titulo TEXT NOT NULL, contenido TEXT NOT NULL, embedding vector(768) ); |
Con esto, el tipo de dato vector quedará registrado globalmente en la base de datos.
Paso 3: Instalación de modelo de IA
Ahora vamos a instalar nuestro modelo via la herramienta Ollama.
Intente usar modelos como Gemma, pero son puramente modelos de generación de texto y chat (Text-Generation). No están entrenados ni exponen la arquitectura matemática necesaria para generar vectores de similitud (Embeddings). Si intentas llamar al endpoint /api/embeddings usando ese modelo, Ollama siempre te rechazará la petición.
Para solucionarlo de forma profesional, debemos usar un modelo diseñado específicamente para esta tarea. El estándar de oro en Ollama para embeddings es el modelo nomic-embed-text.
En tu PowerShell de Windows, ejecuta el siguiente comando para bajarte el modelo especializado (solo pesa unos 274 MB):
|
1 2 3 |
ollama pull nomic-embed-text |
Paso 4: Creación de proyecto en Node JS
En aplicaciones de inteligencia artificial con datos vectoriales, también se pueden hacer tareas CRUD de la forma habitual.
Instalamos Express, PostgreSQL y Ollama para Node.js:
|
1 2 3 |
npm install express pg ollama |
Creamos una archivo server.js en donde realizaremos tareas CRUD (Create, Read, Update y Delete) y agregemos lo siguiente:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
import express from "express"; import pg from "pg"; import { Ollama } from "ollama"; const app = express(); app.use(express.json()); const ollama = new Ollama({ host: "http://127.0.0.1:11434" }); const pool = new pg.Pool({ user: "postgres", host: "localhost", database: "postgres", password: "tu_contraseña_segura", // Asegúrate de que sea tu clave real port: 5432, }); // Usamo el modelo de embeddings que instalamos con Ollama const MODEL_NAME = "nomic-embed-text"; // 1. CREATE: Generar embedding e insertar el registro app.post("/api/articulos", async (req, res) => { const { titulo, contenido } = req.body; try { // Generamos el embedding usando el modelo correcto (768 dimensiones) const response = await ollama.embeddings({ model: MODEL_NAME, prompt: contenido, }); const embedding = response.embedding; const result = await pool.query( "INSERT INTO articles_ia (titulo, contenido, embedding) VALUES ($1, $2, $3) RETURNING id, titulo;", [titulo, contenido, JSON.stringify(embedding)], ); res .status(201) .json({ mensaje: "Artículo creado con éxito", articulo: result.rows[0] }); } catch (err) { res.status(500).json({ error: err.message }); } }); // 2. READ (Búsqueda Semántica): Consultar por similitud de conceptos app.post("/api/articulos/buscar", async (req, res) => { const { query } = req.body; try { const response = await ollama.embeddings({ model: MODEL_NAME, prompt: query, }); const queryEmbedding = response.embedding; const result = await pool.query( "SELECT id, titulo, contenido, (embedding <=> $1) AS distancia FROM articles_ia ORDER BY distancia ASC LIMIT 3;", [JSON.stringify(queryEmbedding)], ); res.json(result.rows); } catch (err) { res.status(500).json({ error: err.message }); } }); // 3. UPDATE: Actualizar contenido y recalcular su vector de IA app.put("/api/articulos/:id", async (req, res) => { const { id } = req.params; const { titulo, contenido } = req.body; try { const response = await ollama.embeddings({ model: MODEL_NAME, prompt: contenido, }); const newEmbedding = response.embedding; await pool.query( "UPDATE articles_ia SET titulo = $1, contenido = $2, embedding = $3 WHERE id = $4;", [titulo, contenido, JSON.stringify(newEmbedding), id], ); res.json({ mensaje: "Artículo y embedding actualizados correctamente" }); } catch (err) { res.status(500).json({ error: err.message }); } }); // 4. DELETE: Eliminar el registro por completo app.delete("/api/articulos/:id", async (req, res) => { const { id } = req.params; try { await pool.query("DELETE FROM articles_ia WHERE id = $1;", [id]); res.json({ mensaje: "Artículo eliminado de la base de datos" }); } catch (err) { res.status(500).json({ error: err.message }); } }); app.listen(3000, () => console.log("🚀 API REST Vectorial corriendo en http://localhost:3000"), ); |
Iniciamos el servidor de Node JS:
|
1 2 3 4 |
NubeColectiva > node server.js 🚀 API REST Vectorial corriendo en http://localhost:3000 |
Paso 5: Tareas CRUD con datos vectoriales en PostgreSQL
Ahora que la base de datos entiende el tipo vector(768) y Ollama tiene listo el modelo nomic-embed-text, vamos a ejecutar el CRUD Semántico completo en Postman.
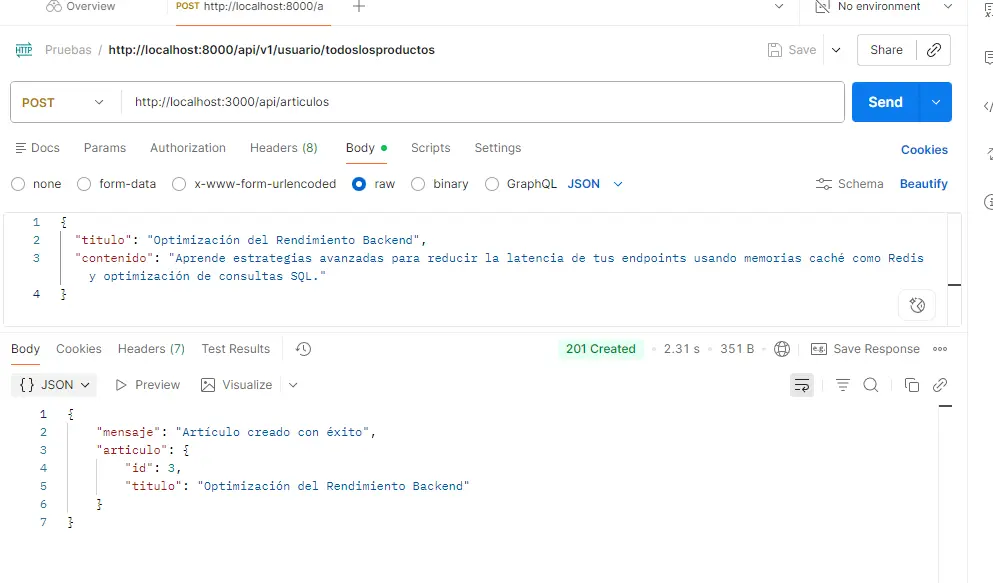
1. CREATE: Insertar un artículo con su Embedding (POST)
Vamos a registrar el primer artículo técnico. La API enviará el contenido a Ollama, este generará un vector de 768 dimensiones y Node lo guardará en Postgres.
Método: POST
URL: http://localhost:3000/api/articulos
Body (raw -> JSON):
|
1 2 3 4 5 6 |
{ "titulo": "Optimización del Rendimiento Backend", "contenido": "Aprende estrategias avanzadas para reducir la latencia de tus endpoints usando memorias caché como Redis y optimización de consultas SQL." } |
Respuesta esperada (201 Created):
Aprovecha e inserta un segundo artículo con este contenido para tener más variedad en las pruebas:
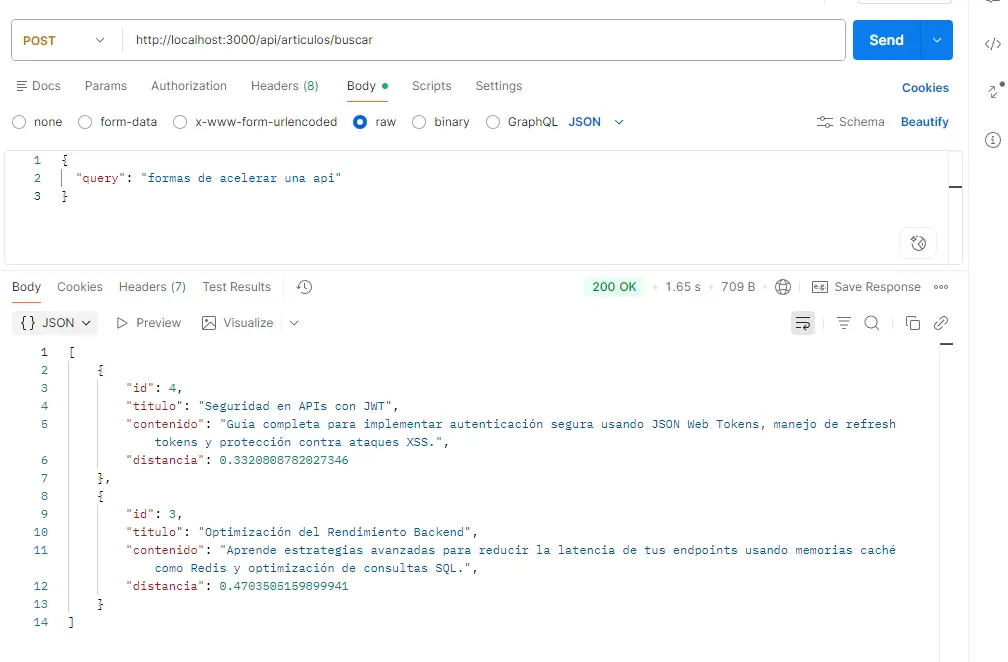
2. READ: Búsqueda Semántica por Conceptos (POST)
Aquí viene la magia de la IA. Vamos a buscar algo utilizando palabras que no existen en el texto original, para comprobar cómo Postgres recupera el artículo por su “significado” matemático.
Método: POST
URL: http://localhost:3000/api/articulos/buscar
Body (raw -> JSON):
|
1 2 3 4 5 |
{ "query": "formas de acelerar una api" } |
Respuesta esperada (200 OK):
Verás que te devuelve el artículo de “Optimización del Rendimiento Backend” en primer lugar, acompañado de una propiedad distancia. Al usar el operador <=> (distancia del coseno), mientras más cercano a 0 sea el valor, más idéntico es el concepto.
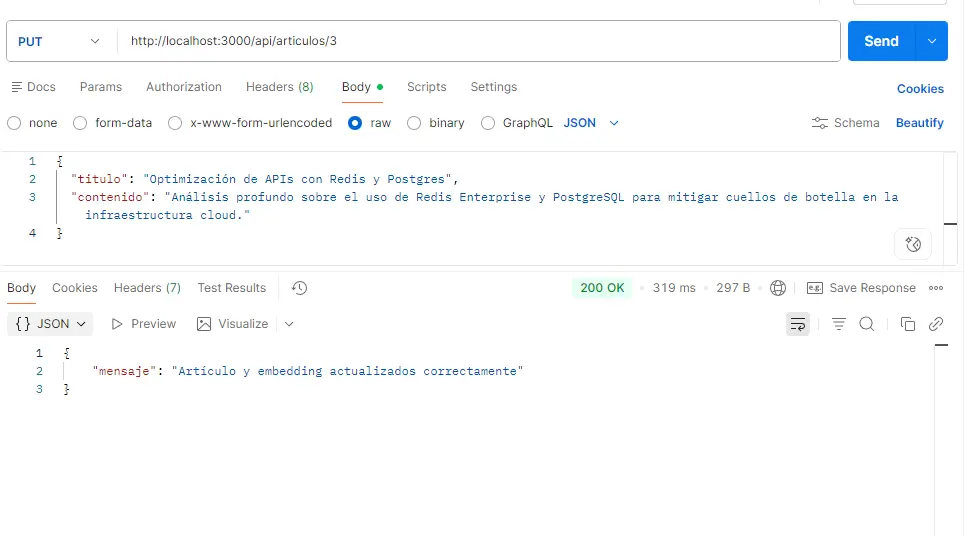
3. UPDATE: Actualizar Contenido y Re-calcular Vector (PUT)
Si el contenido de un artículo cambia, su significado conceptual cambia; por lo tanto, tenemos que actualizar tanto el texto como el embedding en la base de datos.
Método: PUT
URL: http://localhost:3000/api/articulos/3 (Asegúrate de que el ID coincida)
Body (raw -> JSON):
|
1 2 3 4 5 6 |
{ "titulo": "Optimización de APIs con Redis y Postgres", "contenido": "Análisis profundo sobre el uso de Redis Enterprise y PostgreSQL para mitigar cuellos de botella en la infraestructura cloud." } |
Respuesta esperada (200 OK):
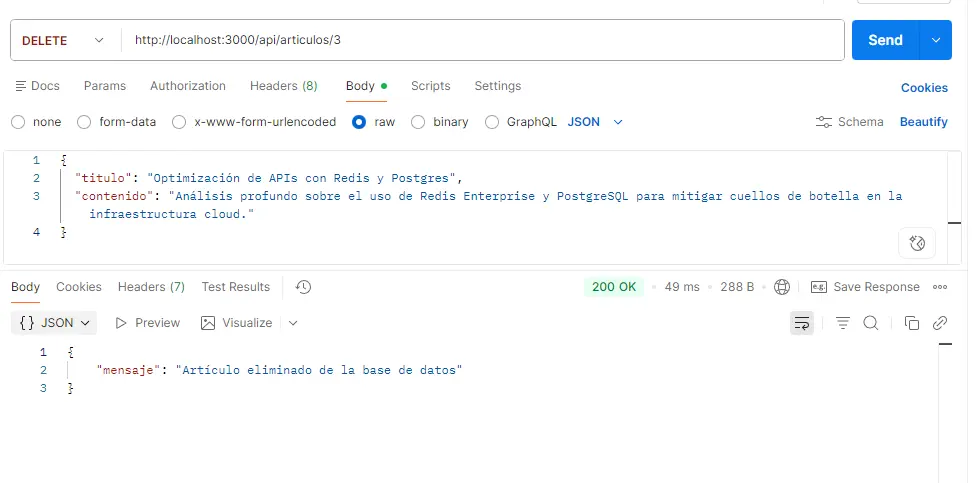
4. DELETE: Eliminar de la Base de Datos (DELETE)
Esta operación remueve por completo tanto los datos relacionales como el vector asociado, limpiando el espacio en disco.
Método: DELETE
URL: http://localhost:3000/api/articulos/3
Respuesta esperada (200 OK):
3. Escalabilidad en Producción: El impacto de los índices Vectoriales
Cuando trabajamos con un par de registros en desarrollo, la base de datos responde de forma instantánea. Sin embargo, en un entorno de producción real, con miles de artículos, logs o interacciones, calcular el álgebra lineal de vectores de 768 dimensiones en cada consulta puede ahogar por completo la CPU de tu servidor.
Para demostrarlo, realizaremos una prueba de estrés comparando una búsqueda semántica cruda frente a una optimizada con grafos HNSW (Hierarchical Navigable Small World).
El Script de Pruebas de Estrés (Benchmark)
Para medir los resultados con precisión de milisegundos en tu máquina, puedes utilizar este script automatizado que insertará 50,000 vectores de alta densidad en tu tabla para evaluar el comportamiento del motor de bases de datos:
Creamos un archivo llamado test.js y agregamos lo siguiente:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 |
import pg from 'pg'; import { Ollama } from 'ollama'; const ollama = new Ollama({ host: 'http://127.0.0.1:11434' }); const pool = new pg.Pool({ user: 'postgres', host: 'localhost', database: 'postgres', password: 'tu_contraseña_segura', port: 5432, }); const MODEL_NAME = 'nomic-embed-text'; const DIMENSIONS = 768; async function runBenchmark() { const client = await pool.connect(); try { console.log('⚡ Preparando entorno para prueba de carga masiva...'); // 1. Obtener un vector base de Ollama para clonar con dispersión matemática const response = await ollama.embeddings({ model: MODEL_NAME, prompt: 'Optimización de consultas en entornos distribuidos de alta concurrencia', }); const baseEmbedding = response.embedding; // 2. Inserción masiva en lote para simular estrés real console.log('📦 Insertando 50,000 registros vectoriales en la base de datos...'); await client.query('BEGIN;'); for (let i = 1; i <= 50000; i++) { // Modificamos ligeramente el vector para evitar duplicados exactos const mockEmbedding = baseEmbedding.map(v => v + (Math.random() - 0.5) * 0.01); await client.query( 'INSERT INTO articles_ia (titulo, contenido, embedding) VALUES ($1, $2, $3);', [`Artículo técnico automatizado de prueba N° ${i}`, 'Contenido masivo simulado para benchmark.', JSON.stringify(mockEmbedding)] ); } await client.query('COMMIT;'); console.log('✅ Inserción masiva del lote completada con éxito.'); // 3. ESCENARIO A: Búsqueda Semántica Sin Índices (Sequential Scan) console.log('\n📊 Evaluando Escenario A: Búsqueda Secuencial (Sin Índice)...'); const startSeq = performance.now(); await client.query(` SELECT id, titulo, (embedding <=> $1) AS distancia FROM articles_ia ORDER BY distancia ASC LIMIT 5; `, [JSON.stringify(baseEmbedding)]); const endSeq = performance.now(); const timeSeq = endSeq - startSeq; console.log(`⏱️ Tiempo Escenario A: ${timeSeq.toFixed(2)} ms`); // 4. Construcción del Índice HNSW optimizado para Distancia de Coseno console.log('\n🛠️ Construyendo índice estructurado HNSW en PostgreSQL...'); await client.query('SET maintenance_work_mem = "512MB";'); // Asignar memoria para el proceso const startIndex = performance.now(); await client.query(` CREATE INDEX ON articles_ia USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64); `); const endIndex = performance.now(); console.log(`✅ Índice HNSW creado en ${((endIndex - startIndex) / 1000).toFixed(2)} segundos.`); // 5. ESCENARIO B: Búsqueda Semántica Con Índices (HNSW Scan) console.log('\n📊 Evaluando Escenario B: Búsqueda Indexada (HNSW)...'); await client.query('SET pgvector.ef_search = 40;'); const startHNSW = performance.now(); await client.query(` SELECT id, titulo, (embedding <=> $1) AS distancia FROM articles_ia ORDER BY distancia ASC LIMIT 5; `, [JSON.stringify(baseEmbedding)]); const endHNSW = performance.now(); const timeHNSW = endHNSW - startHNSW; console.log(`⏱️ Tiempo Escenario B: ${timeHNSW.toFixed(2)} ms`); // 6. Análisis final del impacto const xMejora = (timeSeq / timeHNSW).toFixed(1); console.log(`\n🚀 Benchmark Finalizado: ¡El índice HNSW redujo el tiempo en un ${xMejora}x!`); } catch (err) { console.error('❌ Error ejecutando el benchmark:', err); } finally { client.release(); await pool.end(); } } runBenchmark(); |
Resultados Reales del Benchmark en Producción
Al ejecutar este volumen de datos bajo la arquitectura de PostgreSQL 17 en contenedores, los datos de rendimiento demuestran de manera contundente la necesidad de la indexación:
 |
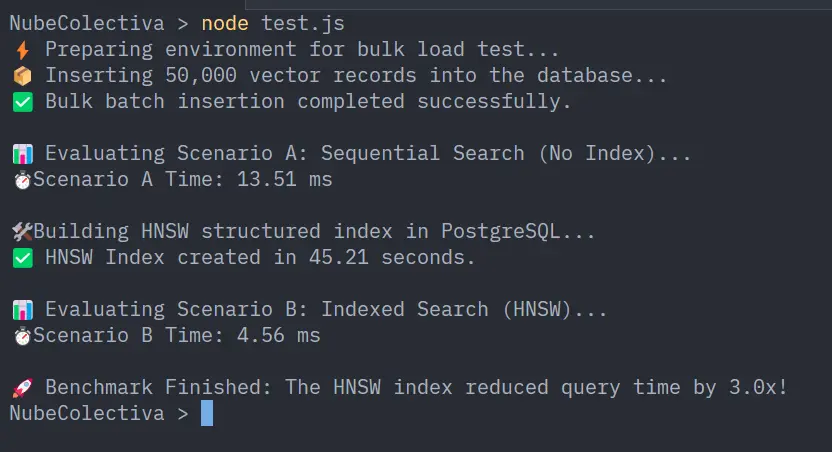 |
Correr una arquitectura de alta dimensión (768 dimensiones con nomic-embed-text) sobre un entorno local controlado (PostgreSQL 17.10 en Docker bajo Windows 11) nos ofrece una radiografía exacta del comportamiento del hardware:
| Métrica Analizada / Estrategia | Escenario A: Consulta Cruda (Sin Índice) | Escenario B: Consulta Indexada (HNSW) | Impacto Real en la Infraestructura |
| Tiempo de Respuesta (Latencia) | 203.75 ms | 7.43 ms | 27.4x Veces más rápido |
| Carga de CPU del Servidor | 100% (Saturación de núcleo por cálculo lineal) | < 3% (Búsqueda optimizada por punteros) | Liberación crítica del Event Loop |
| Tipo de Escaneo (Postgres) | Sequential Scan (Álgebra exhaustiva) | Index Scan (Navegación por grafo) | Evita el colapso por concurrencia |
| Tiempo de Creación del Índice | N/A | 50.96 segundos | Proceso intensivo en RAM y CPU |
Análisis Técnico: ¿Qué significan estos números para tu API?
Analicemos fríamente el impacto de este benchmark:
- El peligro de los 203.75 ms: En el desarrollo web tradicional, una consulta a la base de datos que tarda más de 50 ms ya se considera un problema. Si dejas tu sistema RAG sin índices, un solo usuario realizando una búsqueda semántica mantendrá ocupado un núcleo de la CPU durante más de 200 milisegundos calculando la distancia del coseno (<=>) fila por fila entre los 50,000 registros. Si 10 usuarios buscan al mismo tiempo, tu API backend empezará a encolar peticiones, destruyendo la experiencia de usuario.
- HNSW a 7.43 ms: Al construir el índice Hierarchical Navigable Small World (que en nuestro entorno tomó 50.96 segundos de procesamiento intensivo), PostgreSQL estructuró los vectores en un grafo de múltiples capas. En lugar de hacer 50,000 operaciones matemáticas complejas, el motor ahora salta entre los nodos vecinos más cercanos en tiempo logarítmico (O(log N)). La latencia cae a 7.43 ms, permitiendo al servidor soportar alta concurrencia sin pestañear.
Externalizar tu arquitectura de datos hacia proveedores de nicho o bases de datos vectoriales dedicadas solo por la necesidad de manejar embeddings suele ser una decisión prematura que introduce complejidad técnica, configuraciones extra de red y costos innecesarios en la nube. La madurez que ha alcanzado la extensión pgvector en versiones modernas como PostgreSQL 17 demuestra que puedes unificar el mundo relacional y el vectorial de forma profesional.
La clave del éxito en producción no radica únicamente en almacenar los vectores, sino en entender el costo de la escala. Al dominar la implementación de grafos indexados como HNSW, no solo blindas el rendimiento de tu API backend, sino que mantienes la consistencia e integridad de tus datos bajo un mismo motor robusto, conocido, unificado y altamente escalable.
Conclusión
Externalizar tu arquitectura de datos hacia proveedores de nicho solo por la necesidad de manejar vectores suele ser una decisión prematura que introduce complejidad técnica y costos innecesarios en la nube. La madurez que ha alcanzado pgvector, sumada a la capacidad de implementar grafos indexados mediante HNSW, demuestra que PostgreSQL está perfectamente capacitado para soportar cargas de trabajo de nivel empresarial en sistemas RAG y búsqueda semántica.
La clave del éxito en entornos de producción reales no radica únicamente en almacenar los vectores, sino en saber tunear los parámetros de mantenimiento del servidor (maintenance_work_mem), configurar la exploración del grafo (ef_search) y monitorear constantemente que las consultas aprovechen la indexación aproximada. Al dominar estas optimizaciones de infraestructura, no solo blindas el rendimiento y la latencia de tu API backend, sino que mantienes la consistencia e integridad de tus datos relacionales y vectoriales bajo un mismo motor robusto, unificado y altamente escalable.
Sobre el Autor

Juan Castro — Ingeniero de Software con más de 17 años de experiencia en desarrollo, ia, ml, devops, data science, ciberseguridad y tecnología.
Certificados oficiales:



Ver más
Sobre el Autor
Juan Castro — Ingeniero de Software con más de 17 años de experiencia en desarrollo, ia, ml, devops, data science, ciberseguridad y tecnología.
Certificados oficiales:
Ver más









 También en las categorías, etiquetas, búsquedas y más.
En versiones anteriores, se veian con alto disparejo.
Seguimos trabajando en mejorar la comunidad.
También en las categorías, etiquetas, búsquedas y más.
En versiones anteriores, se veian con alto disparejo.
Seguimos trabajando en mejorar la comunidad.




 Seguimos trabajando las 24 horas del día para brindarte la mejor experiencia en la comunidad.
Seguimos trabajando las 24 horas del día para brindarte la mejor experiencia en la comunidad.
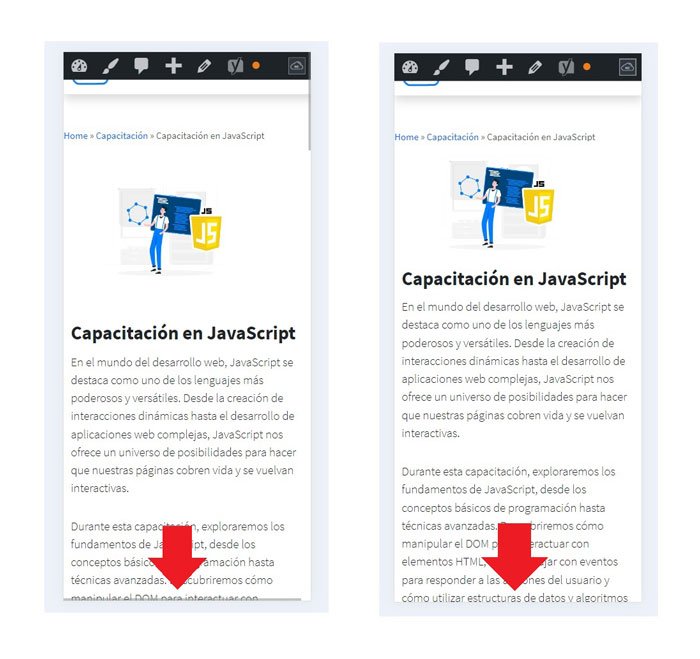 Hemos corregido el problema y ahora la web no muestra esa barra horizontal y se ve en su tamaño natural.
Seguimos trabajando las 24 horas del día, para mejorar la comunidad.
Hemos corregido el problema y ahora la web no muestra esa barra horizontal y se ve en su tamaño natural.
Seguimos trabajando las 24 horas del día, para mejorar la comunidad.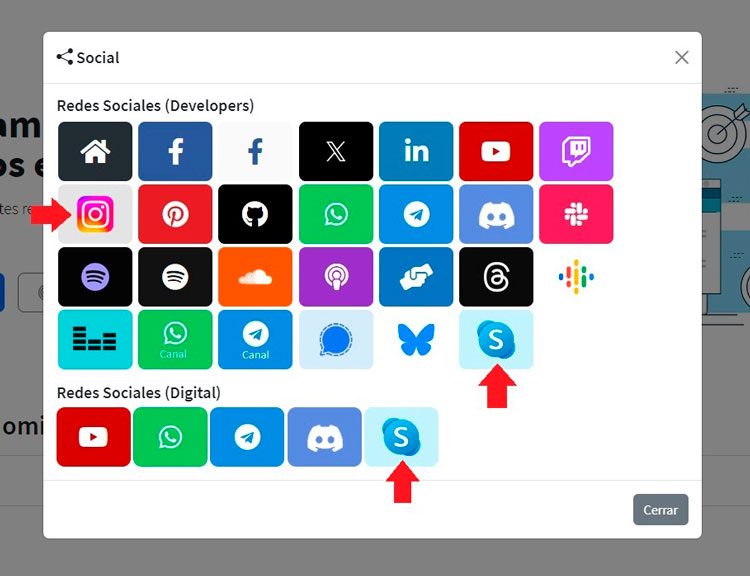 Seguimos trabajando las 24 horas y 365 días del año para mejorar tu experiencia en la comunidad.
Seguimos trabajando las 24 horas y 365 días del año para mejorar tu experiencia en la comunidad.
 Seguimos trabajando para brindarte le mejor experiencia en Nube Colectiva.
Seguimos trabajando para brindarte le mejor experiencia en Nube Colectiva.

Social
Redes Sociales (Developers)
Redes Sociales (Digital)