
Algoritmos de Machine Learning Explicados
 9 minuto(s)
9 minuto(s)En esta página:
- ¿Qué es un algoritmo de Machine Learning?
- Tipos de algoritmos de Machine Learning
- 1. Aprendizaje supervisado (Supervised Learning)
- 2. Aprendizaje no supervisado (Unsupervised Learning)
- 3. Aprendizaje semi-supervisado (Semi-supervised Learning)
- 4. Aprendizaje auto-supervisado (Self-supervised Learning)
- 5. Aprendizaje por refuerzo (Reinforcement Learning)
- 6. Aprendizaje federado (Federated Learning)
- 7. Quantum Machine Learning (QML)
- 8. Aprendizaje adversarial (Adversarial Learning)
- Técnicas modernas y tendencias
- Los algoritmos más usados y cómo funcionan
- ¿Cómo elegir el mejor algoritmo?
- Tecnologías y lenguajes para implementar estos algoritmos
- Ejemplo práctico simple
- Buenas prácticas en Machine Learning
- Métricas de evaluación en Machine Learning
- Consejos finales para aprender y aplicar Machine Learning
- Conclusión
- Fuentes y referencias
El Machine Learning (aprendizaje automático) se ha convertido en una de las ramas más fascinantes e influyentes de la inteligencia artificial. Es la base de tecnologías que usamos a diario, como los filtros de spam en los correos electrónicos, las recomendaciones de Netflix o los asistentes virtuales como Alexa y Siri.
Pero, ¿qué son exactamente los algoritmos de Machine Learning y cómo funcionan?
En este artículo, te lo explicamos de manera sencilla, con ejemplos reales y un repaso por los algoritmos más importantes que todo programador, científico de datos o entusiasta debe conocer.
¿Qué es un algoritmo de Machine Learning?
Un algoritmo de Machine Learning es un conjunto de reglas matemáticas y estadísticas que permite a una máquina aprender a realizar tareas sin ser programada explícitamente para cada una de ellas. En otras palabras, el algoritmo procesa datos, identifica patrones y realiza predicciones o decisiones basadas en esos datos.
Por ejemplo: si alimentas a un algoritmo con datos sobre casas (metros cuadrados, número de habitaciones, ubicación) y los precios a los que se vendieron, el algoritmo puede aprender a estimar el precio de una nueva casa con características similares.
Tipos de algoritmos de Machine Learning
Los algoritmos de Machine Learning se agrupan, de forma general, en las siguientes categorías:
1. Aprendizaje supervisado (Supervised Learning)
En este tipo, el algoritmo aprende a partir de datos etiquetados: cada entrada tiene un resultado conocido.
El objetivo es que, al ver nuevos datos, pueda predecir la etiqueta correcta.
Ejemplos reales:
- Clasificar correos como “spam” o “no spam”.
- Predecir el precio de un coche usado.
Algoritmos comunes:
- Regresión lineal
- Regresión logística
- Árboles de decisión
- Random Forest
- Máquinas de soporte vectorial (SVM)
- k-Nearest Neighbors (k-NN)
2. Aprendizaje no supervisado (Unsupervised Learning)
Aquí el algoritmo trabaja con datos sin etiquetas.
Su tarea es descubrir estructuras ocultas en los datos: agrupar, reducir dimensiones o encontrar patrones.
Ejemplos reales:
- Agrupar clientes con comportamientos similares para marketing.
- Detección de fraudes sin ejemplos previos.
Algoritmos comunes:
- Clustering (agrupamiento), como K-means
- Algoritmos de reducción de dimensionalidad, como PCA (Análisis de Componentes Principales)
- Modelos de mezcla gaussiana
3. Aprendizaje semi-supervisado (Semi-supervised Learning)
Aquí el algoritmo trabaja con una combinación de datos etiquetados y no etiquetados.
El objetivo es aprovechar los datos sin etiquetar (que suelen ser abundantes) para mejorar el rendimiento del modelo que se entrena con pocos datos etiquetados.
Es útil cuando etiquetar datos es costoso o requiere expertos (por ejemplo, en medicina).
Ejemplos reales:
- Clasificación de imágenes médicas donde solo algunas tienen diagnóstico confirmado.
- Sistemas de recomendación que mezclan ratings explícitos con el comportamiento implícito del usuario.
Algoritmos comunes:
- Self-training (auto-entrenamiento): el modelo se autoetiqueta progresivamente los datos no etiquetados.
- Co-training: combina dos modelos diferentes que se entrenan entre sí.
- Graph-based methods: usa grafos para propagar etiquetas en los datos.
- Semi-supervised SVM (S3VM): adapta SVM para datos parcialmente etiquetados.
4. Aprendizaje auto-supervisado (Self-supervised Learning)
En este caso, el algoritmo genera sus propias etiquetas a partir de los datos no etiquetados mediante tareas auxiliares (pretext tasks).
El objetivo es aprender una representación útil de los datos que luego puede ser utilizada en tareas supervisadas con pocos datos.
Es la base de muchos avances recientes en inteligencia artificial, especialmente en visión por computadora y procesamiento de lenguaje natural.
Ejemplos reales:
- Modelos de lenguaje como BERT o GPT, donde el modelo aprende prediciendo palabras ocultas en un texto.
- Redes de visión que predicen partes faltantes de una imagen o el orden de fragmentos.
Algoritmos y técnicas comunes:
- Contrastive learning (SimCLR, MoCo): el modelo aprende a distinguir datos similares y distintos.
- Masked modeling: el modelo predice partes ocultas (ej. Masked Language Model de BERT).
- Autoencoders y variational autoencoders (VAE): el modelo aprende a codificar y decodificar los datos.
- BYOL (Bootstrap Your Own Latent): técnica de visión sin necesidad de contraste negativo.
Contrastive learning (SimCLR, MoCo): el modelo aprende a distinguir datos similares y distintos. Masked modeling: el modelo predice partes ocultas (ej. Masked Language Model de BERT). Autoencoders y variational autoencoders (VAE): el modelo aprende a codificar y decodificar los datos. BYOL (Bootstrap Your Own Latent): técnica de visión sin necesidad de contraste negativo.
5. Aprendizaje por refuerzo (Reinforcement Learning)
En este enfoque, el algoritmo toma decisiones en un entorno y aprende a maximizar una recompensa.
No recibe etiquetas directas, sino señales de qué tan bien lo está haciendo.
Ejemplos reales:
- Robots que aprenden a caminar.
- Inteligencias artificiales que juegan videojuegos (como AlphaGo de Google).
Algoritmos comunes:
- Q-learning
- Deep Q-Networks (DQN)
- Proximal Policy Optimization (PPO)
6. Aprendizaje federado (Federated Learning)
Aquí el algoritmo se entrena en múltiples dispositivos o nodos de forma descentralizada, sin que los datos salgan de los dispositivos.
El objetivo es proteger la privacidad de los datos mientras se construyen modelos globales.
Es ideal en entornos donde los datos son sensibles o no se pueden compartir fácilmente (por ejemplo, por leyes de privacidad).
Ejemplos reales:
- Predicción de texto o autocorrector en teléfonos móviles (Google Gboard).
- Modelos de detección de fallos en dispositivos IoT (Internet de las cosas).
Algoritmos y técnicas comunes:
- Federated Averaging (FedAvg): los dispositivos entrenan localmente y luego combinan sus modelos de forma segura.
- Secure aggregation: técnicas criptográficas que aseguran que las actualizaciones se combinan sin exponer datos.
- Personalized federated learning: adapta el modelo global a cada dispositivo.
7. Quantum Machine Learning (QML)
Aquí el algoritmo de Machine Learning aprovecha principios de la computación cuántica (como la superposición o el entrelazamiento) para realizar tareas de aprendizaje más rápido o de forma más eficiente.
Aunque todavía es un campo en desarrollo, tiene gran potencial para problemas complejos que requieren gran capacidad de cómputo.
Ejemplos reales (en investigación o pruebas):
- Clasificación de moléculas para el descubrimiento de fármacos.
- Optimización de rutas en logística usando circuitos cuánticos.
Algoritmos y técnicas comunes:
- Variational Quantum Circuits: redes cuánticas entrenables que mezclan puertas cuánticas con optimización clásica.
- Quantum Support Vector Machines: versión cuántica de los SVM.
- Quantum k-means: clustering acelerado con estados cuánticos.
- QAOA (Quantum Approximate Optimization Algorithm): para problemas combinatorios.
8. Aprendizaje adversarial (Adversarial Learning)
En este tipo de aprendizaje, el objetivo es enseñar a los modelos a ser robustos frente a intentos de engañarlos.
También se usa en modelos donde dos redes compiten (como las GAN).
Es clave para la seguridad y la fiabilidad de los sistemas de Machine Learning.
Ejemplos reales:
- Detectar y resistir ataques donde pequeñas modificaciones en imágenes engañan a un sistema de visión artificial (por ejemplo, cambiar un stop por un yield).
- Redes Generativas Adversariales (GANs) que crean imágenes realistas (ej. deepfakes).
Algoritmos y técnicas comunes:
- Generative Adversarial Networks (GAN): dos redes (generador y discriminador) compiten para producir datos realistas.
- FGSM (Fast Gradient Sign Method): técnica para generar ejemplos adversariales.
- PGD (Projected Gradient Descent): método más fuerte para ataques adversariales.
- Defensive distillation: técnica para hacer modelos más resistentes.
Nota: Hemos clasificado los Tipos de algoritmos de Machine Learning (paradigmas de aprendizaje de Machine Learning) en 8 grandes tipos por su relevancia práctica y actualidad. Existen además otros enfoques como el aprendizaje activo, transfer learning o multi-task learning que se usan en combinación con estos paradigmas principales.
En la siguiente imagen puedes conocer todos los Tipos de Algoritmos de Machine Learning que existen, junto con las tecnologías, lenguajes de programación y bases de datos que utilizan:
 |
 |
Técnicas modernas y tendencias
En la actualidad han aparecido nuevas formas de trabajar con aprendizaje automático:
Ensambles y meta‑algoritmos
Incluyen Bagging (Random Forest), Boosting (AdaBoost, Gradient Boosting), Stacking.
Deep Learning y arquitecturas
Desde CNN, RNN, transformadores, hasta redes generativas tipo GAN y self-supervised models .
Explainable AI (XAI)
Métodos como LIME, SHAP o XQML que buscan interpretar modelos complejos.
AutoML y No‑code ML
Automatización de selección de modelos, optimización de hiperparámetros; muy potente para democratización.
Self‑Supervised Learning
Modelos aprenden de grandes volúmenes de datos sin etiquetar; son el eje en visión y NLP reciente
Los algoritmos más usados y cómo funcionan
A continuación puedes ver los algoritmos que estan siendo más usados en la industria del aprendizaje automático:
Regresión lineal
Es el más simple: intenta ajustar una línea recta a los datos que minimice la diferencia entre las predicciones y los valores reales.
Se usa mucho en predicciones de precios, ventas, etc.
Regresión logística
Aunque su nombre diga “regresión”, es un algoritmo de clasificación: predice la probabilidad de que algo pertenezca a una clase (por ejemplo, “positivo” o “negativo”).
Árboles de decisión
Dividen los datos en ramas basadas en preguntas (¿el ingreso es mayor a 50K? ¿la edad es menor a 30?) y terminan en una predicción.
Son fáciles de interpretar.
Random Forest
Es un conjunto de árboles de decisión.
La idea es que un grupo de árboles “vote” por el resultado, lo que hace que las predicciones sean más precisas y robustas.
Máquinas de soporte vectorial (SVM)
Encuentran la frontera que mejor separa las clases en el espacio de datos.
Es muy potente en problemas donde las clases no se separan de forma sencilla.
K-means
Un algoritmo de agrupamiento que intenta formar grupos (clusters) de datos similares.
El número de grupos (K) lo defines tú.
Redes neuronales
Inspiradas en el cerebro humano, consisten en capas de “neuronas” conectadas que pueden aprender relaciones muy complejas.
Se usan en visión por computadora, procesamiento de voz, etc.
¿Cómo elegir el mejor algoritmo?
No existe el “mejor algoritmo” universal. Depende de:
- El tipo de problema (clasificación, regresión, agrupamiento).
- El tamaño y calidad de los datos.
- La interpretación que necesites (por ejemplo, los árboles de decisión son fáciles de entender; las redes neuronales no tanto).
- El tiempo de cómputo disponible.
Lo recomendable es probar varios algoritmos y comparar sus resultados usando métricas como precisión, recall, F1 score, MAE (error absoluto medio), etc.
Tecnologías y lenguajes para implementar estos algoritmos
Los algoritmos de Machine Learning se implementan normalmente usando:
- Python (Lenguaje de programación): el lenguaje más usado gracias a librerías como scikit-learn, TensorFlow, PyTorch, XGBoost.
- R (Lenguaje de programación): muy popular en estadística y análisis de datos.
- Julia: un lenguaje más reciente, con buen rendimiento en cálculos numéricos.
También se pueden usar entornos como:
- Jupyter Notebook: para documentar y correr experimentos.
- Google Colab: una alternativa gratuita en la nube.
Ejemplo práctico simple
Veamos un mini ejemplo con Python y scikit-learn para una regresión lineal:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from sklearn.linear_model import LinearRegression import numpy as np # Datos de ejemplo: tamaño de la casa (m2) y precio X = np.array([[50], [60], [80], [100], [120]]) y = np.array([150, 180, 240, 300, 360]) # Crear y entrenar el modelo modelo = LinearRegression() modelo.fit(X, y) # Predecir el precio de una casa de 90 m2 prediccion = modelo.predict([[90]]) print(f"Precio estimado: {prediccion[0]} mil USD") # Salida esperada: Precio estimado cercano a 270 mil USD. |
Buenas prácticas en Machine Learning
En tus proyectos de aprendizaje automático, considera:
Separar los datos en conjuntos de entrenamiento, validación y prueba
Así evitamos que el modelo “memorice” los datos y se vuelva inútil en el mundo real (sobreajuste).
Usar validación cruzada (cross-validation)
Por ejemplo, K-fold: el modelo se entrena y prueba varias veces con diferentes divisiones de los datos.
Esto da una evaluación más robusta.
Elegir la métrica adecuada para el problema
Por ejemplo:
- En medicina → Prioriza recall (mejor detectar de más que dejar pasar un enfermo).
- En marketing de spam → Prioriza precision (no queremos molestar al usuario marcando correos buenos como spam).
Controlar el sobreajuste (overfitting)
El sobreajuste es cuando el modelo aprende demasiado bien los datos de entrenamiento y falla en nuevos datos.
¿Cómo evitarlo?
- Regularización (L1, L2)
- Early stopping (detener el entrenamiento cuando el rendimiento en validación empeora)
- Aumentar datos o usar técnicas como dropout (en redes neuronales)
Revisar la calidad de los datos
Un buen modelo no arregla datos sucios.
Limpia datos, maneja los valores faltantes, normaliza si hace falta.
Documenta y explica los resultados
La interpretabilidad es clave, especialmente si tu modelo impacta en personas (ej. créditos, diagnósticos).
Prueba varios modelos y compara
No te cases con uno solo.
A veces el modelo más simple (como una regresión) puede funcionar tan bien como una red neuronal compleja.
Métricas de evaluación en Machine Learning
Las métricas son números que nos ayudan a medir qué tan bien o mal está funcionando un modelo.
No basta con entrenarlo: debemos evaluar su rendimiento de forma objetiva.
Para clasificación (cuando el modelo asigna categorías: spam/no spam, enfermo/sano)
En esta tarea debes considerar las siguientes métricas:
1. Accuracy (Exactitud)
Mide el porcentaje de predicciones correctas.
Fácil de entender.
No es buena si hay clases desbalanceadas (por ejemplo, 95% sanos, 5% enfermos).
Ejemplo: de 100 casos, si acertamos en 90 → accuracy = 90%.
2. Precision (Precisión)
De los que el modelo dijo que eran positivos, ¿cuántos lo son realmente?
Útil cuando el costo de un falso positivo es alto (ej. detectar spam).
Fórmula: Verdaderos positivos / (Verdaderos positivos + Falsos positivos)
3. Recall (Sensibilidad o Tasa de verdaderos positivos)
De los casos realmente positivos, ¿cuántos detectó el modelo?
Importante si queremos detectar todos los positivos (ej. cáncer, fraudes).
Fórmula: Verdaderos positivos / (Verdaderos positivos + Falsos negativos)
4. F1-score
Es el balance entre precision y recall.
Útil cuando hay desbalance de clases.
Fórmula: 2 * (Precision * Recall) / (Precision + Recall)
5. AUC-ROC (Área bajo la curva ROC)
Mide qué tan bien el modelo distingue entre clases.
Cuanto más cerca de 1, mejor.
Para regresión (cuando el modelo predice valores numéricos: precio de una casa, temperatura)
En esta tarea debes considerar las siguientes métricas:
1. MAE (Mean Absolute Error – Error absoluto medio)
Promedio de la diferencia en valor absoluto entre la predicción y el valor real.
Fácil de entender porque está en las mismas unidades (ej. $).
2. MSE (Mean Squared Error – Error cuadrático medio)
Promedio del cuadrado de los errores.
Penaliza más los errores grandes (porque los eleva al cuadrado).
3. RMSE (Root Mean Squared Error – Raíz del MSE)
Raíz cuadrada del MSE, para volver a las unidades originales.
Ejemplo real de estas métricas
Imagina que un modelo predice si un correo es spam.
- Precision alta: casi todo lo que dice que es spam lo es.
- Recall alto: casi todos los spams son detectados.
- F1-score alto: buen equilibrio.
- Accuracy alta: bien si las clases están balanceadas, pero cuidado si no.
Consejos finales para aprender y aplicar Machine Learning
- Entiende tus datos antes de aplicar algoritmos. La exploración previa (EDA) es clave.
- Nunca te quedes con un solo modelo. Compara y valida.
- Cuida el sobreajuste (overfitting). Los modelos demasiado complejos pueden memorizar en lugar de generalizar.
- Practica con datasets reales. Por ejemplo, los de Kaggle, UCI Machine Learning Repository.
Conclusión
Los algoritmos de Machine Learning son el corazón del aprendizaje automático. Conocerlos, entender cómo funcionan y saber cuándo usarlos te abre la puerta a un mundo lleno de posibilidades, desde aplicaciones sencillas hasta sistemas de IA avanzados.
En Nube Colectiva, te animamos a seguir explorando y experimentando para que conviertas el aprendizaje automático en una herramienta poderosa en tus proyectos.
Síguenos en nuestras Redes Sociales y demás canales digitales para que no te pierdas nuestros próximos contenidos.
Fuentes y referencias
- Géron, Aurélien. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow (O’Reilly, 2022).
- Bishop, Christopher. Pattern Recognition and Machine Learning (Springer, 2006).
- Documentación oficial de scikit-learn.
- Google AI Blog.
Sobre el Autor

Juan Castro — Ingeniero de Software con más de 17 años de experiencia en desarrollo, ia, ml, devops, data science, ciberseguridad y tecnología.
Certificados oficiales:



Ver más
Sobre el Autor
Juan Castro — Ingeniero de Software con más de 17 años de experiencia en desarrollo, ia, ml, devops, data science, ciberseguridad y tecnología.
Certificados oficiales:
Ver más







 También en las categorías, etiquetas, búsquedas y más.
En versiones anteriores, se veian con alto disparejo.
Seguimos trabajando en mejorar la comunidad.
También en las categorías, etiquetas, búsquedas y más.
En versiones anteriores, se veian con alto disparejo.
Seguimos trabajando en mejorar la comunidad.




 Seguimos trabajando las 24 horas del día para brindarte la mejor experiencia en la comunidad.
Seguimos trabajando las 24 horas del día para brindarte la mejor experiencia en la comunidad.
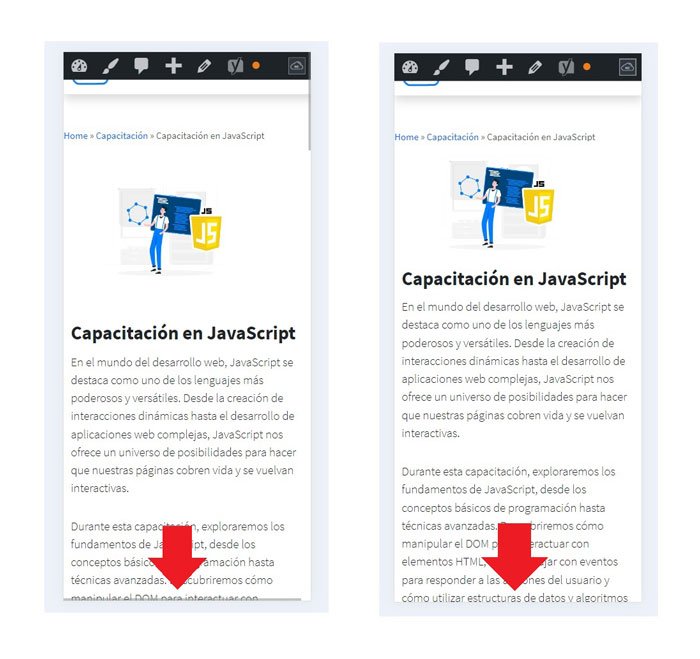 Hemos corregido el problema y ahora la web no muestra esa barra horizontal y se ve en su tamaño natural.
Seguimos trabajando las 24 horas del día, para mejorar la comunidad.
Hemos corregido el problema y ahora la web no muestra esa barra horizontal y se ve en su tamaño natural.
Seguimos trabajando las 24 horas del día, para mejorar la comunidad. Seguimos trabajando las 24 horas y 365 días del año para mejorar tu experiencia en la comunidad.
Seguimos trabajando las 24 horas y 365 días del año para mejorar tu experiencia en la comunidad.
 Seguimos trabajando para brindarte le mejor experiencia en Nube Colectiva.
Seguimos trabajando para brindarte le mejor experiencia en Nube Colectiva.

Social
Redes Sociales (Developers)
Redes Sociales (Digital)