

En la parte anterior llamada Manejo Profesional de Errores con Python – Parte 1, vimos ciertos métodos y conceptos teóricos con códigos de ejemplo, para manejar los errores del código de nuestros proyectos en Python. Asimismo vimos una jerarquía de excepciones con las cuales podemos trabajar de manera segura nuestras excepciones con Python, en esta segunda y última parte veremos otros conceptos y métodos para hacer un Manejo Profesional de Errores con Python, vamos con ello.
Partes
- Parte 1
- Parte 2 (Final)

Antes de continuar te invito a leer los siguiente artículos:
- Que es Python y otros Detalles
- Como Ejecutar Código Python Dentro de Código HTML
- Como Funciona el Método callable() de Python
- Como Crear Nuestro Primer Programa o Software Ejecutable con Python
- 10 Razones por las Cuales deberías aprender Python – Parte 1
- Diferencia entre los métodos sort() y sorted() en Python
- Puedes leer más Posts en la categoría Python
Asimismo, te invito a escuchar el Podcast: “Porque El Lenguaje De Programación Python Es Tan Popular” y “¿ Se Debe Escuchar Música Mientras Se Programa ?” (Anchor Podcast):
| Spotify: | Sound Cloud: | Apple Podcasts | Anchor Podcasts |
 |
 |
 |
 |

Bien ahora continuemos con el Post: Manejo Profesional de Errores con Python – Parte 2 (Final).
Cláusula Final
A veces, deseas asegurarte que se ejecute algún código de limpieza incluso si se generó una excepción en algún momento del camino. Por ejemplo, puedes tener una conexión de base de datos que deseas cerrar una vez que hayas terminado. Esta es la forma incorrecta de hacerlo:
def obtener_datos():
db = open_db_connection()
query(db)
close_db_Connection(db)
Si la función query() genera una excepción, la llamada close_db_connection() nunca se ejecutará y la conexión a la base de datos permanecerá abierta. La cláusula finally siempre se ejecuta después de que se ejecuta un controlador de excepciones Try All. Aquí está cómo hacerlo correctamente:
def obtener_datos():
db = None
try:
db = open_db_connection()
query(db)
finally:
if db is not None:
close_db_connection(db)
La llamada a open_db_connection() no puede devolver una conexión o generar una excepción en sí misma. En este caso, no es necesario cerrar la conexión a la base de datos.
Al usar finally, debes tener cuidado de no generar ninguna excepción allí porque enmascararán la excepción original.
Administradores de contexto
Los administradores de contexto brindan otro mecanismo para envolver recursos como archivos o conexiones de bases de datos en código de limpieza que se ejecuta automáticamente incluso cuando se generan excepciones. En lugar de bloques try-finally, usa la declaración with. Aquí hay un ejemplo con un archivo:
def procesar_archivo(nombrearchivo):
with open(nombrearchivo) as f:
process(f.read())
Ahora, incluso si process() genera una excepción, el archivo se cerrará correctamente, inmediatamente cuando with se salga del alcance del bloque, independientemente de si la excepción se manejó o no.
Inicio sesión
El registro es prácticamente un requisito en los sistemas no triviales de larga duración. Es especialmente útil en aplicaciones web donde puedes tratar todas las excepciones de forma genérica: simplemente registra la excepción y devuelve un mensaje de error a la persona que llama.
Al iniciar sesión, es útil registrar el tipo de excepción, el mensaje de error y el seguimiento de la pila. Toda esta información está disponible a través del objeto sys.exc_info, pero si usas el método logger.exception() en tu controlador de excepciones, el sistema de registro de Python extraerá toda la información relevante por ti.
Esta es la mejor práctica que recomiendo:
import logging
logger = logging.getLogger()
def miFuncion():
try:
flaky_func()
except Exception:
logger.exception()
raise
Si sigues este patrón (asumiendo que configuraste el registro correctamente), pase lo que pase, tendrás un registro bastante bueno de lo que salió mal y podrás solucionar el problema.
Si vuelves a generar la excepción, asegúrate de no registrar la misma excepción una y otra vez en diferentes niveles. Es un desperdicio, y puede confundirte y hacerte pensar que se produjeron varias instancias del mismo problema, cuando en la práctica se registró una sola instancia varias veces.
La forma más sencilla de hacerlo es dejar que todas las excepciones se propaguen (a menos que puedan manejarse con confianza antes) y luego realizar el registro cerca del nivel superior de tu aplicación.
Sentry
El registro es una capacidad. La implementación más común es el uso de archivos de registro. Pero, para sistemas distribuidos a gran escala con cientos, miles o más servidores, esta no siempre es la mejor solución.
Para realizar un seguimiento de las excepciones en toda tu infraestructura, un servicio como Sentry es muy útil. Centraliza todos los informes de excepciones y, además del seguimiento de la pila, agrega el estado de cada marco de la pila (el valor de las variables en el momento en que se generó la excepción). También proporciona una interfaz realmente agradable con paneles, informes y formas de desglosar los mensajes por múltiples proyectos. Es de código abierto, por lo que puedes ejecutar tu propio servidor o suscribirte a la versión alojada.
A continuación se muestra una captura de pantalla que muestra cómo Sentry muestra los errores en tu aplicación de Python:
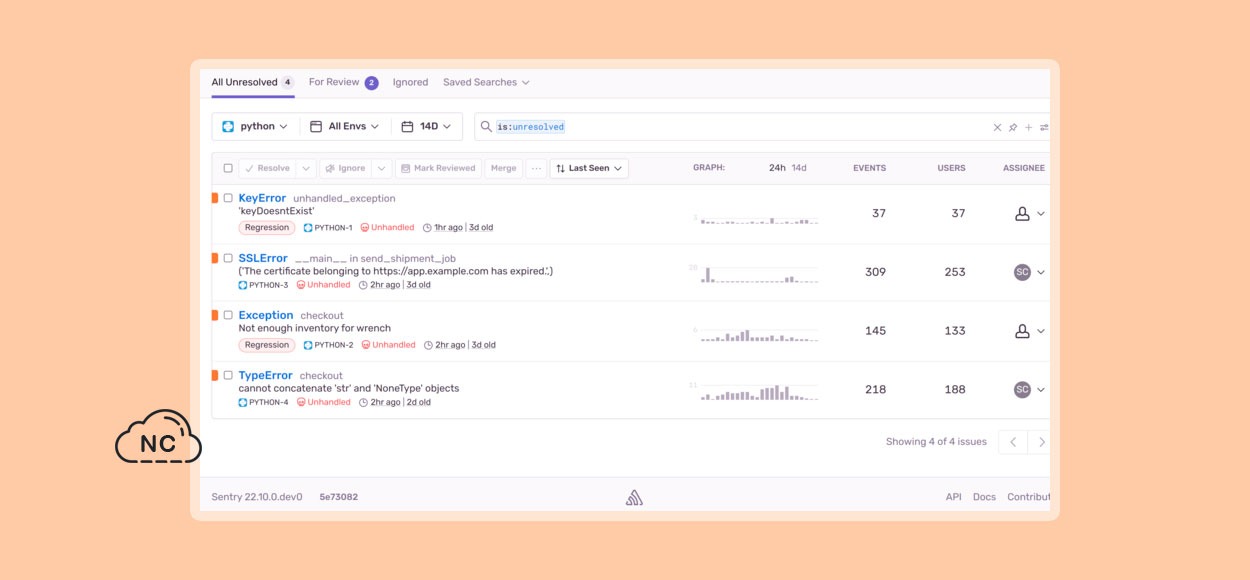
Y aquí hay un seguimiento de pila detallado del archivo que causa el error:
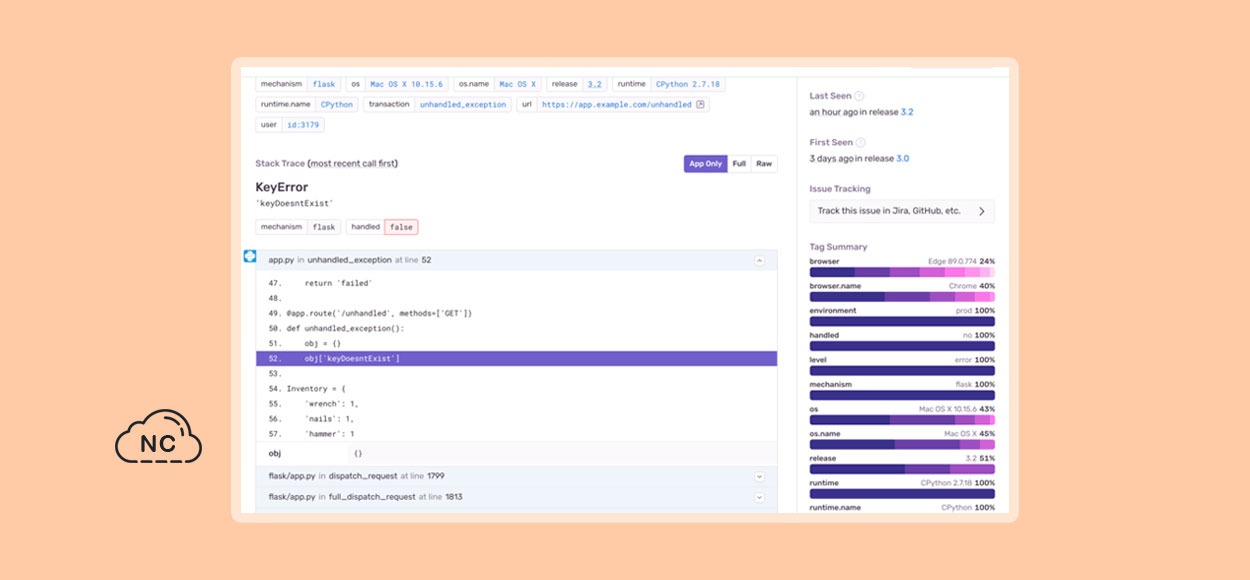
Algunas fallas son temporales, en particular cuando se trata de sistemas distribuidos. Un sistema que se asusta a la primera señal de problemas no es muy útil.
Si tu código está accediendo a algún sistema remoto que no responde, la solución tradicional son los tiempos de espera, pero a veces no todos los sistemas están diseñados con tiempos de espera. Los tiempos de espera no siempre son fáciles de calibrar a medida que cambian las condiciones.
Otro enfoque es fallar rápido y luego volver a intentarlo. El beneficio es que si el objetivo está respondiendo rápidamente, entonces no tienes que pasar mucho tiempo en estado de sueño y puedas reaccionar de inmediato. Pero si fallas, puedes volver a intentarlo varias veces hasta que decidas que es realmente inalcanzable y genere una excepción.
En la siguiente sección, presentaré un decorador que puede hacerlo por ti.
Decoradores Útiles
Dos decoradores que pueden ayudar con el manejo de errores son el @log_error, que registra una excepción y luego la vuelve a generar, y el decorador @retry, que volverá a intentar llamar a una función varias veces.
Registrador de errores
Aquí hay una implementación simple. El decorador exceptúa un objeto registrador. Cuando decora una función y se invoca la función, envolverá la llamada en una cláusula try-except, y si hubo una excepción, la registrará y finalmente generará la excepción nuevamente:
def log_error(logger)
def decorated(f):
@functools.wraps(f)
def wrapped(*args, **kwargs):
try:
return f(*args, **kwargs)
except Exception as e:
if logger:
logger.exception(e)
raise
return wrapped
return decorated
Y así puedes usarlo:
import logging
logger = logging.getLogger()
@log_error(logger)
def f():
raise Exception('Yo soy un crack de la programación')
Recuperador
Aquí hay una muy buena implementación del decorador @retry:
import time
import math
# Reintentar el decorador con retroceso exponencial
def retry(tries, delay=3, backoff=2):
'''Vuelve a intentar una función o método hasta que devuelva True.
delay establece el retraso inicial en segundos, y backoff establece el factor por el cual
la demora debe alargarse después de cada falla. el retroceso debe ser mayor que 1,
o de lo contrario no es realmente un retroceso. intentos debe ser al menos 0, y el retraso
mayor que 0.''''
if backoff <= 1:
raise ValueError("el retroceso debe ser mayor que 1")
tries = math.floor(tries)
if tries < 0:
raise ValueError("los intentos deben ser 0 o más")
if delay <= 0:
raise ValueError("el retraso debe ser mayor que 0")
def deco_retry(f):
def f_retry(*args, **kwargs):
mtries, mdelay = tries, delay # hacer mutable
rv = f(*args, **kwargs) # primer intento
while mtries > 0:
if rv is True: # Terminado con éxito
return True
mtries -= 1 # consumir un intento
time.sleep(mdelay) # esperar...
mdelay *= backoff # hacer que el futuro espere más
rv = f(*args, **kwargs) # Intentar de nuevo
return False # Ran out of tries :-(
return f_retry # true decorator -> función decorated
return deco_retry # @retry(arg[, ...]) -> true decorator
Hasta aquí llegamos con algunos de los conceptos más importantes que debes conocer para hacer un Manejo más Profesional de Errores con Python.
Conclusión
En este Post que consta de dos partes has aprendido ciertos métodos, técnicas y concejos para realizar una manejo de errores más profesional. LA mejor forma de dominar estas técnicas, es usándolas en tus proyectos.
Nota (s)
- No olvides que debemos usar la Tecnología para hacer cosas Buenas por el Mundo.
Síguenos en nuestras Redes Sociales para que no te pierdas nuestros próximos contenidos.