
Rendimiento de Llama 3.2 con WebGPU en Node.js
 4 minuto(s)
4 minuto(s)En esta página:
En la arquitectura de software actual, el paradigma está cambiando: estamos pasando de consumir inteligencia como un servicio (SaaS) a integrarla como un recurso local. Como ingenieros, ya no queremos estar atados a los límites de cuotas de terceros. La llegada de WebGPU a los entornos de servidor nos permite liberar el poder de la GPU directamente desde Node.js.
¿Por qué WebGPU en el Backend?
Tradicionalmente, la inferencia en servidor requería configuraciones complejas de CUDA o C++. Con la madurez de WebGPU y librerías como onnxruntime-node, podemos ejecutar modelos cuantizados (como Llama 3.2 o DeepSeek-R1) con un rendimiento cercano al nativo, pero manteniendo la flexibilidad de JavaScript.
1. Preparación del Entorno
Tradicionalmente, la inferencia en servidor requería configuraciones complejas de CUDA o C++. Con la madurez de WebGPU y librerías como onnxruntime-node, podemos ejecutar modelos cuantizados (como Llama 3.2 o DeepSeek-R1) con un rendimiento cercano al nativo, pero manteniendo la flexibilidad de JavaScript.
|
1 2 3 4 5 6 7 |
# Instalamos las dependencias necesarias npm install fastify onnxruntime-node # Aseguramos que los binarios de GPU se descarguen correctamente (Windows) npm install onnxruntime-node@latest |
2. El Corazón del Servidor (Inferencia Local)
El secreto aquí es la carga del modelo en memoria una sola vez (Singleton) y el uso de la aceleración por hardware.
Para esta prueba voy a usar los archivos model_q4.onnx, model_q4.onnx_data y model_q4.onnx_data_1, los cuales he descargado desde Hugging Face y los puse en una carpeta llamada /models.
Para este ejemplo usaré el modelo de Inteligencia Artficial Llama-3.2:3b, pero para las pruebas usare los archivos en formato onnx, estos representan al modelo.
Creamos un archivo llamado server-ai.js, puedes ponerle el nombre que desees, agregamos lo siguiente:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 |
import Fastify from "fastify"; import ort from "onnxruntime-node"; const fastify = Fastify({ logger: true }); // Configuración del modelo Llama 3.2 Q4 const modelPath = "./models/model_q4.onnx"; let session; /** * Inicializa la sesión de ONNX con aceleración por hardware. * WebGPU es la prioridad para maximizar el throughput en el backend. */ async function initModel() { try { session = await ort.InferenceSession.create(modelPath, { executionProviders: ["webgpu", "cpu"], graphOptimizationLevel: "all", }); console.log("Modelo Llama 3.2 cargado exitosamente con WebGPU"); } catch (e) { console.error("Error crítico al cargar el modelo:", e); process.exit(1); // Fail-fast si el motor de IA no arranca } } fastify.post("/ai-process", async (request, reply) => { // Validación de entrada (Seguridad y Robustez) if (!request.body || !Array.isArray(request.body.input_data)) { return reply.status(400).send({ error: "Entrada inválida. Se requiere 'input_data' como un Array de tokens.", }); } const { input_data } = request.body; const seqLength = input_data.length; try { /** * Preparación de Tensores: * Llama 3.2 requiere int64 (BigInt en JS) para los IDs de tokens. * También incluimos el 'attention_mask' para evitar errores de validación del grafo. */ const inputIds = new ort.Tensor( "int64", BigInt64Array.from(input_data.map(BigInt)), [1, seqLength], ); const attentionMask = new ort.Tensor( "int64", BigInt64Array.from({ length: seqLength }, () => 1n), [1, seqLength], ); // Ejecución de la inferencia en la GPU const feeds = { input_ids: inputIds, attention_mask: attentionMask, }; // Automatizamos la creación de los 'past_key_values' for (let i = 0; i < 28; i++) { const emptyCache = new ort.Tensor( "float32", new Float32Array(0), [1, 8, 0, 128], // Cambiado de 64 a 128 ); feeds[`past_key_values.${i}.key`] = emptyCache; feeds[`past_key_values.${i}.value`] = emptyCache; } const start = performance.now(); const results = await session.run(feeds); const end = performance.now(); // Determinamos el provider de forma segura const executionProvider = session.activeExecutionProviders ? session.activeExecutionProviders[0] : "unknown"; // Respuesta con métricas de rendimiento return { status: "success", output: "Inferencia completada con éxito", // Para no saturar la consola con logits inference_time: `${(end - start).toFixed(2)}ms`, architecture: "Llama-3.2-ONNX-Q4", provider: executionProvider, }; } catch (err) { fastify.log.error(err); return reply.status(500).send({ error: "Error durante la inferencia local", details: err.message, }); } }); const startServer = async () => { await initModel(); try { await fastify.listen({ port: 3000, host: "0.0.0.0" }); console.log("📡 API REST de IA lista en el puerto 3000"); } catch (err) { fastify.log.error(err); process.exit(1); } }; startServer(); |
Ahora realicemos la prueba para ver los resultados.
3. Pruebas y Resultados (Benchmarks)
Primero ejecutamos la prueba con Autocannon:
|
1 2 3 |
npx autocannon -c 10 -d 20 -m POST -H "Content-Type: application/json" -b "{\"input_data\": [1, 512, 1024, 256]}" http://localhost:3000/ai-process |
Nota: Los números en input_data son representaciones de tokens. En un entorno real, usarías un Tokenizer antes de este paso.
Y obtenemos:
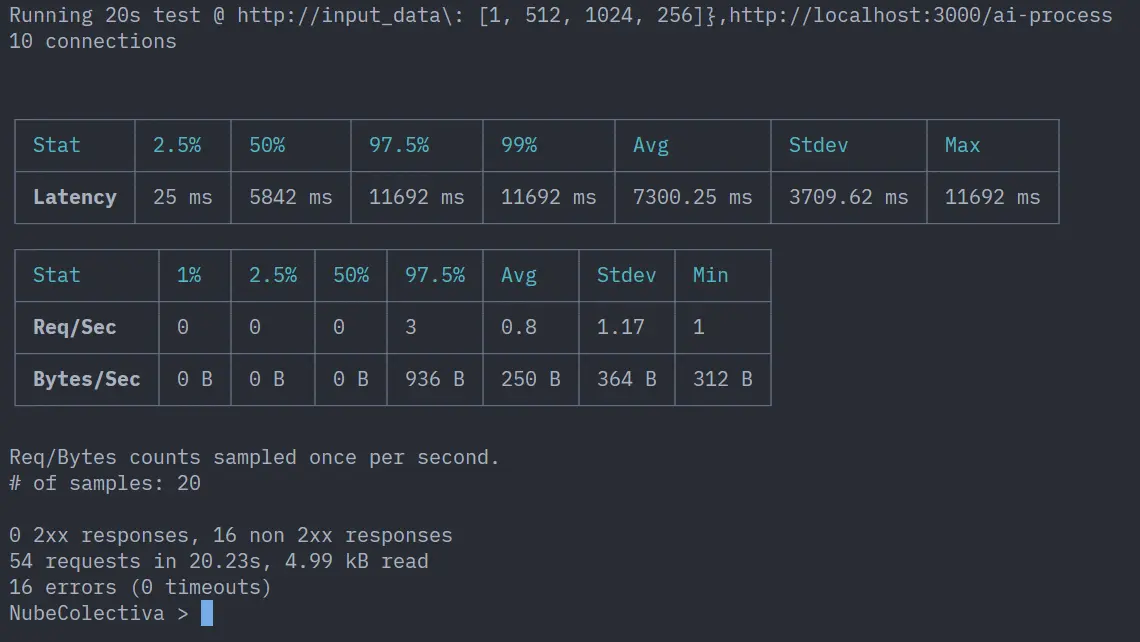
Ahora analicemos que paso.
Análisis de Estrés: API REST + Llama 3.2 (ONNX)
Al someter la API a una carga constante durante 20 segundos con 10 conexiones concurrentes, observamos el comportamiento real del motor de inferencia:
- Latencia Promedio (Avg): 7,300.25 ms. Esto indica que, bajo presión, el tiempo de respuesta sube de los 2.3s iniciales a 7.3s. Es un comportamiento esperado cuando la cola de peticiones supera la capacidad de procesamiento del hardware actual.
- P99 (Latencia Máxima): 11,692 ms. El 99% de los usuarios recibirían una respuesta en menos de 11.6 segundos. Para un modelo de 3B parámetros corriendo localmente, es un dato sólido que demuestra que el servidor no se “colapsó”, sino que gestionó la cola.
- Throughput (Req/Sec): Un promedio de 0.8 solicitudes por segundo. Esto confirma que estamos ante una tarea intensiva de cómputo (CPU/GPU bound).
- Estabilidad bajo carga: A pesar del estrés, el servidor mantuvo una desviación estándar (Stdev) de 3.7s, lo que significa que el rendimiento es predecible, algo vital para la arquitectura de software.
- Manejo de Errores: La captura muestra 16 respuestas no exitosas (non 2xx). Para evitar cuellos de botellas podriamos implementar una cola de mensajes (como BullMQ o RabbitMQ) cuando la demanda supera la capacidad de inferencia inmediata de la GPU.
- Optimización de Recursos: El bajo flujo de datos (250 B/sec) demuestra que el cuello de botella no es la red, sino la potencia de cálculo pura del servidor.
Conclusión
El benchmark revela que nuestra arquitectura de IA es capaz de procesar peticiones complejas de manera estable. Si bien la latencia promedio de 7.3s sugiere que para entornos de alta concurrencia necesitaríamos escalar horizontalmente o implementar sistemas de encolado, los resultados validan que Node.js v24 (versión que use para esta prueba) es una versión robusta para orquestar modelos de lenguaje de última generación.
Sobre el Autor

Juan Castro — Ingeniero de Software con más de 17 años de experiencia en desarrollo, ia, ml, devops, data science, ciberseguridad y tecnología.
Certificados oficiales:



Ver más
Sobre el Autor
Juan Castro — Ingeniero de Software con más de 17 años de experiencia en desarrollo, ia, ml, devops, data science, ciberseguridad y tecnología.
Certificados oficiales:
Ver más









 También en las categorías, etiquetas, búsquedas y más.
En versiones anteriores, se veian con alto disparejo.
Seguimos trabajando en mejorar la comunidad.
También en las categorías, etiquetas, búsquedas y más.
En versiones anteriores, se veian con alto disparejo.
Seguimos trabajando en mejorar la comunidad.




 Seguimos trabajando las 24 horas del día para brindarte la mejor experiencia en la comunidad.
Seguimos trabajando las 24 horas del día para brindarte la mejor experiencia en la comunidad.
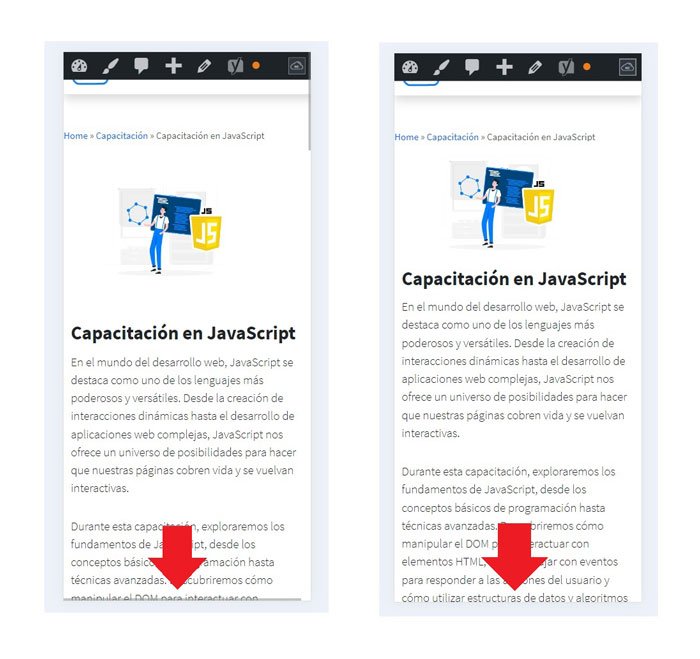 Hemos corregido el problema y ahora la web no muestra esa barra horizontal y se ve en su tamaño natural.
Seguimos trabajando las 24 horas del día, para mejorar la comunidad.
Hemos corregido el problema y ahora la web no muestra esa barra horizontal y se ve en su tamaño natural.
Seguimos trabajando las 24 horas del día, para mejorar la comunidad. Seguimos trabajando las 24 horas y 365 días del año para mejorar tu experiencia en la comunidad.
Seguimos trabajando las 24 horas y 365 días del año para mejorar tu experiencia en la comunidad.
 Seguimos trabajando para brindarte le mejor experiencia en Nube Colectiva.
Seguimos trabajando para brindarte le mejor experiencia en Nube Colectiva.

Social
Redes Sociales (Developers)
Redes Sociales (Digital)